新能源汽车消费者调研
EV Cars Customer Insight Report
Tips: 点击每个section右上角的
code即可选择全部默认显示代码
- 课程:北京大学战略管理学
- 姓名:杨谨行
- 学号:W18194067
- 小组:Group2
# rm(list = ls())
# setwd(dirname(rstudioapi::getActiveDocumentContext()$path))
# setwd(dirname(rstudioapi::getActiveDocumentContext()$path))
source("FUNCS.R")
source("FUNCS_plotly.R")
source("FUNCS_ggplot2.R")
#library(esquisse)
if(!require("corrplot")) install.packages("corrplot") # used for making correlation plot.
if(!require("psych")) install.packages("psych") # used for Factor Analysis
if(!require("car")) install.packages("car") # used for calculating VIF, to check multicollinearity
if(!require("factoextra")) install.packages("factoextra") # clustering algorithms & visualization
if(!require("xtable")) install.packages("xtable") # show regression table
if(!require("nFactors")) install.packages("nFactors")
replace_na <- tidyr::replace_na
renew_data <- function(){
read_excel("data/2021_04_29_02_11_56.xlsx") %>% slice(2:n()) %>% mutate_all(~ifelse(is.na(.x), "-",.x))}
#### 数据导入 ####
factor_to_int <- function(x) as.numeric(as.character(x))
# 知识
knowledge_raw = rev(c(
"非常了解",
"比较了解",
"只了解些大概",
"只是听过,不了解",
"没怎么听过,不了解",
"完全不了解也没听过"))
knowledge_value = 0:5
encode_knowledge <- function(x){
factor_to_int(
factor(x,
levels = knowledge_raw,
labels = knowledge_value))
}
decode_knowledge <- function(x){
factor(x,
levels = knowledge_value,
labels = knowledge_raw)
}
# 买车类型
cartype_raw = c(
"传统车(汽油车、柴油车及非充电的油电混合车等)",
"新能源车:插电式混合动力车纯电动车",
"新能源车:纯电动车",
"其他新能源车")
cartype_value = c(
"传统车",
"混动车",
"纯电车",
"其他新能源车"
)
encode_cartype <- function(x){
factor(x,
levels = cartype_raw,
labels = cartype_value)
}
# 买车间隔
buygap_raw = c(
"1个月或1个月内",
"1个月(不含)~3个月(含)",
"3个月(不含)~6个月(含)",
"6个月(不含)~1年(含)",
"1年(不含)~2年(含)",
"2年(不含)~3年(含)",
"3年(不含)~5年(含)",
"5年(不含)~7年(含)",
"7年内都没有买车打算,原因是:")
buygap_value = c(
0.5,
2,
4.5,
9,
12+6,
12*2+6,
12*4,
6*12,
7*12
)
buygap_string = c(
"1个月或1个月内",
"1~3个月",
"6个月~1年",
"1~2年",
"2~3年",
"3~5年",
"5~7年",
"7年内都没有买车打算")
encode_buygap <- function(x){
factor_to_int(
factor(x,
levels = buygap_raw,
labels = buygap_value))
}
decode_buygap <- function(x){
factor(x,
levels = buygap_value,
labels = buygap_string)
}
# 买车预算
budget_raw = c(
"-",
"<10万",
">=10万且<15万",
">=15万且<20万",
">=20万且<30万",
">=30万且<40万",
">=40万且<50万",
">=50万且<60万",
">=60万")
budget_value = c(
0,
5,
12.5,
17.5,
25,
35,
45,
55,
65
) * 10000
encode_budget <- function(x){
factor_to_int(
factor(x,
levels = budget_raw,
labels = budget_value))
}
decode_budget <- function(x){
factor(x,
levels = budget_value,
labels = budget_raw)
}
# 同意程度
agree_raw = rev(c(
"完全同意",
"同意",
"有些同意",
"认为无差异",
"有些不同意",
"不同意",
"完全不同意"))
agree_value = rev(c(
3,
2,
1,
0,
-1,
-2,
-3
))
encode_agree <- function(x){
factor_to_int(
factor(x,
levels = agree_raw,
labels = agree_value))
}
decode_agree <- function(x){
factor(x,
levels = agree_value,
labels = agree_raw)
}
# 资讯获取主动度
check_raw = rev(c(
"会时不时地主动了解",
"基本不会主动了解,但有资讯推送时会经常查看",
"基本不会主动了解,但有资讯推送时会偶尔会点开看",
"不会主动了解、收到推送也会忽略"))
check_value = 0:3
encode_check <- function(x){
factor_to_int(
factor(x,
levels = check_raw,
labels = check_value))
}
decode_check <- function(x){
factor(x,
levels = check_value,
labels = check_raw)
}1 数据准备
1.1 数据清洗与处理
设计的问卷题目一共40题,问卷样例请见 credamo问卷链接
- Part 1.拥车情况与购车计划
- Part 2.车辆外观与性能因素
- Part 3.车辆续航因素
- Part 4.车辆品牌与价格因素
- Part 5.车辆使用场景因素
- Part 6.个人信息与社交媒体使用情况
- 以及问卷的作答信息
其中涉及的5类值标签通过以下字典转换为数值(interval / ordinal):
data <- read_excel("data/2021_04_29_02_11_56.xlsx") %>%
slice(2:n()) %>%
# 标记NA
dplyr::mutate_all(~ifelse(is.na(.x), "-",.x))read_excel("data/EVCars_6个部分全部.xlsx",sheet=2) -> temp
temp %>% filter(!is.na(类型)) %>%
select(1,3,2) %>%
get_DT(pageLength = 10)清洗后的数据 呈现如下:
1.1.1 拥车现状与购车综合意愿
如果想了解具体的清洗步骤,可以点击右侧的Code👉
data %>%
# 批量改一下列名
rename_at(vars(`您在考虑是否买新能源车时,以下因素中对您起关键决定性作用的五个(以最重要的因素开始选择)-获取牌照的难度`:`您在考虑是否买新能源车时,以下因素中对您起关键决定性作用的五个(以最重要的因素开始选择)-售后服务`),
~paste0(gsub("您在考虑是否买新能源车时,以下因素中对您起关键决定性作用的五个(以最重要的因素开始选择)-|(耐久度等)|的","",.x), "重要性")) %>%
transmute(
作答ID,
了解程度 = encode_knowledge(您对新能源车的了解程度),
#了解程度标签 = decode_knowledge(了解程度),
拥车辆 = as.integer(gsub("台", "", `您的家庭当前拥有多少台车`)), # 问卷问了34 但是只有012
# 第1台车的情况
第一台车类型 = case_when(
拥车辆 == 1 ~`您的家庭当前拥有的车的具体情况(<p> </p>-车辆类型)`,
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第一台-车辆类型)`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第一台-车辆类型)`
),
第一台车购买场景 = case_when(
拥车辆 == 1 ~`您的家庭当前拥有的车的具体情况(<p> </p>-购买场景)`,
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第一台-购买场景)`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第一台-购买场景)`
),
第一台车汽车单价 = case_when(
拥车辆 == 1 ~`您的家庭当前拥有的车的具体情况(<p> </p>-汽车单价)`,
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第一台-汽车单价)`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第一台-汽车单价)`
),
第一台车购车年份 = case_when(
拥车辆 == 1 ~`您的家庭当前拥有的车的具体情况(<p> </p>-购车年份(4位))`,
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第一台-购车年份(4位))`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第一台-购车年份(4位))`
),
# 第2台车的情况
第二台车类型 = case_when(
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第二台-车辆类型)`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第二台-车辆类型)`
),
第二台车购买场景 = case_when(
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第二台-购买场景)`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第二台-购买场景)`
),
第二台车汽车单价 = case_when(
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第二台-汽车单价)`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第二台-汽车单价)`
),
第二台车购车年份 = case_when(
拥车辆 == 2 ~`您的家庭当前拥有的2台车的具体情况(第二台-购车年份(4位))`,
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第二台-购车年份(4位))`
),
# 第3台车的情况
第三台车类型 = case_when(
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第三台-车辆类型)`
),
第三台车购买场景 = case_when(
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第三台-购买场景)`
),
第三台车汽车单价 = case_when(
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第三台-汽车单价)`
),
第三台车购车年份 = case_when(
拥车辆 == 3 ~`您的家庭当前拥有的3台车的具体情况(第三台-购车年份(4位))`
),
下次买车间隔月数 = encode_buygap(`您的家庭计划在多久后买第一台车(或下一台车):`),
下次买车预算 = encode_budget(`您的家庭计划买第一台车(或下一台车)的预算大概是:单位:人民币 元`),
买新能源车概率 = case_when(
下次买车间隔月数 == 7*12 ~ `如果未来有开车的需求和充足的预算,您有多大概率会买新能源车-买新能源车的概率(%)`,
下次买车间隔月数 != 7*12 ~ `您的家庭第一台车(或下一台车)多大概率会买新能源车-买新能源车的概率(%)`
),
买新能源车概率 = as.numeric(买新能源车概率) / 100,
下台车购买计划 = case_when(
买新能源车概率 <= 0.33 ~ "买传统车",
买新能源车概率 >= 0.66 ~ "买新能源车",
T ~ "不确定"
),
获取牌照难度重要性,充电体验重要性,续航里程重要性,汽车价格重要性,后续维修保养开销重要性,车辆保值情况重要性,车辆质量重要性,外观重要性,环保重要性,补贴或免税政策重要性,品牌形象重要性,车辆驾驶性能重要性,车辆乘坐体验重要性,售前服务重要性,售后服务重要性
) %>%
# 数据清洗
mutate_at(c("第一台车购车年份","第二台车购车年份","第三台车购车年份"),
~as.numeric(gsub("年","",.x))) %>%
mutate_at(c("第一台车类型","第二台车类型","第三台车类型"),
~encode_cartype(.x)) %>%
mutate_at(vars(获取牌照难度重要性:售后服务重要性),
~ifelse(is.na(.x) | .x == "-", 6, as.numeric(.x))) %>%
fillna_at(vars(获取牌照难度重要性:售后服务重要性),1) -> data_part_1
# 买车综合情况
temp = list()
for(col in c("第一台","第二台","第三台")){
data_part_1 %>%
select(作答ID,
contains(paste0(col,"车类型")),
contains(paste0(col,"车汽车单价")),
contains(paste0(col, "车购车年份"))) %>%
set_colnames(c("作答ID", "车辆类型", "车辆单价", "购车年份"))-> temp[[col]]
}
bind_rows(temp) %>%
filter_at(2:ncol(.), all_vars(!is.na(.))) -> car_info
# 提取车价信息
car_info %>%
group_by(作答ID) %>%
filter(购车年份 == max(购车年份)) %>%
mutate_at("车辆单价", ~ifelse(.x == "60万元以上", ">=60万", .x)) %>%
transmute(最后一台车单价 = encode_budget(车辆单价),
距上次买车 = 2021 - 购车年份) %>%
left_join(data_part_1 %>% select(作答ID),.) %>%
fillna_at("最后一台车单价", 0) %>%
ungroup %>%
mutate(距上次买车 = replace_na(距上次买车, max(距上次买车, na.rm=T))) -> last_car_info
data_part_1 %<>% left_join(last_car_info)
data_part_1 %>%
keep(is.numeric) %>%
gather() %>%
ggplot(aes(value)) +
facet_wrap(~ key, scales = "free") +
geom_histogram() + ppt_text -> p
ggplotly(p)- 其中:重要性从1~5表示消费者的购买决策前五项排名,6为缺失填充,具体数据展示如下:
data_part_1 %>% get_DT()1.1.2 车辆外观与性能因素
如果想了解具体的清洗步骤,可以点击右侧的Code👉
data %>%
# 批量改一下列名
rename_at(vars(`与相比传统车相比,下列对新能源车的说法您的感受是?-新能源汽车的外观设计更符合我的偏好`:`与相比传统车相比,下列对新能源车的说法您的感受是?-电动汽车电池老化快`),
~gsub("与相比传统车相比,下列对新能源车的说法您的感受是?-","",.x)) %>%
#select_at(vars(新能源汽车的外观设计更符合我的偏好:电动汽车电池老化快)) %>%
#colnames() -> temp; paste0(temp,collapse = "`,`")
transmute(
作答ID,
`新能源汽车的外观设计更符合我的偏好`,
`新能源汽车有更先进的驾驶功能(自动驾驶及辅助驾驶等)`,`新能源汽车的人机交互系统体验更好`,`新能源汽车的安全性能(耐环境性、误操作防护及事故保护等)更好`,`新能源汽车的质量(零件不易损坏等)更好`,`新能源汽车的车内噪声更低`,`新能源汽车驾驶及乘坐舒适度更好(如更平稳等)`,`新能源汽车的起步加速更快`,`目前新能源车的续航不足`,`电动汽车充电不方便(如公共充电桩太少、家用充电桩不容易装等)`,`电动汽车电池老化快`
) %>%
mutate_at(2:ncol(.), ~encode_agree(ifelse(.x == "一般", "认为无差异", .x))) %>%
left_join(
data %>%
transmute(
作答ID,
预期百公里加速 = as.numeric(`如果买新能源汽车,符合您要求的车至少要达到的百公里加速百公里加速指的是0到100km/h加速时间,是对汽车动力最直观的一种体现。比如,特斯拉Model 3为5.35秒、小鹏P7为6.63秒-<p> </p>`
))) -> data_part_2
data_part_2 %>% get_DT()1.1.3 车辆续航要求
如果想了解具体的清洗步骤,可以点击右侧的Code👉
data %>%
transmute(
作答ID,
续航里程要求 = `如果买新能源汽车,符合您要求的车至少要达到的续航里程-<p> </p>`,
家用充电桩充电时间要求 = `如果购买了电动汽车,您使用家用充电桩时,最长能够接受的充电时间-<p> </p>`,
公共充电桩充电时间要求 = `如果购买了电动汽车,您外出使用公共充电桩时,最长能够接受的充电时间(不含来回时间)-<p> </p>`,
充电路程时间要求 = `如果购买了电动汽车,您最长能够接受多少分钟的车程内有充电桩?0分钟表示:必须有条件装家用充电桩才会考虑买电动车-<p> </p>`) %>%
as.numeric_at(2:5) -> data_part_3
data_part_3 %>% get_DT()1.1.4 车辆品牌与价格因素
如果想了解具体的清洗步骤,可以点击右侧的Code👉
data %>%
group_by(作答ID) %>%
select_at(vars(`如果购买新能源车,以下品牌您会更倾向于-比亚迪(BYD)`:`如果购买新能源车,以下品牌您会更倾向于-大众`)) %>%
rename_at(vars(`如果购买新能源车,以下品牌您会更倾向于-比亚迪(BYD)`:`如果购买新能源车,以下品牌您会更倾向于-大众`),
~paste0(
"倾向",
gsub("如果购买新能源车,以下品牌您会更倾向于-","",.x))) %>%
select(-倾向长城欧拉) -> data_part_4_brand
data %>%
group_by(作答ID) %>%
transmute(
新能源车意愿价位 = factor(`您能接受的新能源汽车价位?单位:人民币 元` ,
level = c("<10万",
">=10万且<15万",
">=15万且<20万",
">=20万且<30万",
">=30万且<40万",
">=40万且<50万",
">=50万且<60万",
">=60万")),
新能源车意愿溢价 = as.numeric(`相比传统车,您愿意为新能源车付出的溢价是-<p> </p>`),
汽车意愿年均使用成本 = as.numeric(`您能接受的汽车每年平均的使用费用(平均维修、保养)-<p> </p>`),
汽车意愿五年折价率 = as.numeric(`您能接受的汽车在买入5年后的保值率(5年后的二手价能保持在新车原价的多少)-<p> </p>`) / 100
) -> data_part_4_price
target = vars(`与相比传统车相比,下列对新能源车的说法您的感受是?-新能源汽车购买时会享有更多政府优惠补贴 或 购置税减免政策政策`:`与相比传统车相比,下列对新能源车的说法您的感受是?-新能源汽车维修保养的开销更大`)
data %>%
group_by(作答ID) %>%
transmute_at(target,
encode_agree) %>%
rename_at(target,
~paste0(
"",
gsub("与相比传统车相比,下列对新能源车的说法您的感受是?-新能源汽车|的|[[:space:]]","",.x))) -> data_part_4_policy
data_part_4_brand %>%
left_join(data_part_4_price) %>%
left_join(data_part_4_policy) -> data_part_4
data_part_4 %>% get_DT()1.1.5 车辆使用场景因素
如果想了解具体的清洗步骤,可以点击右侧的Code👉
target = vars(
`与相比传统车相比,下列对新能源车的说法您的感受是?-新能源汽车上牌更容易`:
`与相比传统车相比,下列对新能源车的说法您的感受是?-新能源汽车更加环保`)
pre_text = "与相比传统车相比,下列对新能源车的说法您的感受是?-"
data %>%
group_by(作答ID) %>%
transmute_at(target, ~encode_agree(ifelse(.x == "一般", "认为无差异", .x))) %>%
rename_at(target,
~paste0(
"",
gsub(pre_text,"",.x))) %>%
left_join(
data %>%
group_by(作答ID) %>%
transmute(日常通勤来回路程 = as.numeric(`您日常平均每天出行的里程(来回)?-<p> </p>`)),.) -> data_part_5
data_part_5 %>% get_DT()1.1.6 个人信息与社交媒体使用情况
如果想了解具体的清洗步骤,可以点击右侧的Code👉
data = renew_data()
data %>%
group_by(作答ID) %>%
transmute(
性别 = 您的性别,
年龄 = 2021 - as.numeric(`您的出生年份(4位)`),
婚姻状况 = 您当前的婚姻状况,
家庭成员数 = as.numeric(gsub("人|及以上", "",`您共同生活的家庭成员的人数(包括自己)`)),
学历 = 您的最高学历,
所在地 = 您目前生活的城市,
家庭月收入 = as.numeric(`您家庭大致的每月平均收入(万元人民币)-<p> </p>`)*10000,
职业 = ifelse(您的主职业 == "其他", `您的主职业-其他-文本`, 您的主职业 ),
资讯获取主动度 = encode_check(`对于汽车品牌在社交网络发布的内容(如产品发布信息等)`)) %>%
#mutate
separate(所在地,sep = ",", into = c("省份","城市")) -> data_part_6_1
target <- vars(`您了解或接触汽车信息的渠道-亲朋好友`:`您了解或接触汽车信息的渠道-其他`)
pre_text = "您了解或接触汽车信息的渠道-"
data %>%
group_by(作答ID) %>%
transmute_at(target, ~.x) %>%
rename_at(target,
~paste0(
"",
gsub(pre_text,"",.x))) -> data_part_6_2
target <- vars(c(`您了解或接触汽车信息的渠道-汽车专业论坛-文本`, `您了解或接触汽车信息的渠道-社交媒体(微信、知乎、小红书等)-文本`, `您了解或接触汽车信息的渠道-网络视频平台(抖音、快手等)-文本`,
`您了解或接触汽车信息的渠道-其他-文本`))
pre_text = "您了解或接触汽车信息的渠道-|-文本"
data %>%
group_by(作答ID) %>%
transmute_at(target,~gsub("。|都有", "", .x)) %>%
transmute_at(target,~gsub(",|[[:space:]]|、", "、", .x)) %>%
rename_at(target,
~paste0(
"",
gsub(pre_text,"",.x))) -> temp
temp %>%
separate_rows(c("汽车专业论坛",
"社交媒体(微信、知乎、小红书等)",
"网络视频平台(抖音、快手等)",
"其他"
),sep = "、") %>%
set_colnames(c("作答ID", c("a","b","c","d"))) %>%
transmute(
途径 = paste0(c(a,b,c,d), collapse = "、")) %>%
separate_rows(途径,sep = "、") %>%
filter(途径!="-") %>%
mutate(有 = 1,
途径 = paste0("从", 途径)) %>% unique %>%
pivot_wider(id_cols = "作答ID",
names_from = 途径,
values_from = 有) -> data_part_6_3
data_part_6_1 %>%
left_join(data_part_6_2) %>%
left_join(data_part_6_3) -> data_part_6
data_part_6 %>% get_DT()1.1.7 用户问卷信息
如果想了解具体的清洗步骤,可以点击右侧的Code👉
data %>%
select(作答ID:随机元素) -> user_info
user_info %>% get_DT()# 输出
list("Part1-拥车现状与购车综合意愿" = data_part_1,
"Part2-车辆外观与性能因素" = data_part_2,
"Part3-车辆续航要求" = data_part_3,
"Part4-车辆品牌与价格因素" = data_part_4,
"Part5-车辆使用场景因素" = data_part_5,
"Part6-个人信息与社交媒体使用情况" = data_part_6) -> datas
# 整合
datas_all = data %>% distinct_at(1)
for(name in names(datas)){
datas_all %<>% left_join(datas[[name]])
}
data_all <- datas_all
datas_all## # A tibble: 193 × 114
## 作答ID 了解程度 拥车辆 第一台车类型 第一台车购买场景 第一台车汽车单价
## <chr> <dbl> <int> <fct> <chr> <chr>
## 1 oZbi2E2Q4PRi 5 1 混动车 替换旧车(被替换旧… >=20万且<30万
## 2 dR9iYltl4PRu 4 1 传统车 家庭第一辆车 >=15万且<20万
## 3 mqeKuP974PR0 5 1 纯电车 替换旧车(被替换旧… >=20万且<30万
## 4 NCoUnKWK4PEN 4 1 传统车 家庭第一辆车 >=15万且<20万
## 5 axx8wjlG4PEK 4 1 传统车 家庭第一辆车 >=15万且<20万
## 6 Ha9ubotb4PEJ 4 1 传统车 家庭第一辆车 >=10万且<15万
## 7 piLAllfa4PEG 3 1 传统车 家庭第一辆车 >=15万且<20万
## 8 bRCMahEk4PEI 4 2 纯电车 家庭第一辆车 <10万
## 9 eMaYz8oC4PEY 4 1 传统车 家庭第一辆车 >=10万且<15万
## 10 USi0gkEf4PEm 3 1 纯电车 家庭第一辆车 >=10万且<15万
## # … with 183 more rows, and 108 more variables: 第一台车购车年份 <dbl>,
## # 第二台车类型 <fct>, 第二台车购买场景 <chr>, 第二台车汽车单价 <chr>,
## # 第二台车购车年份 <dbl>, 第三台车类型 <fct>, 第三台车购买场景 <chr>,
## # 第三台车汽车单价 <chr>, 第三台车购车年份 <dbl>, 下次买车间隔月数 <dbl>,
## # 下次买车预算 <dbl>, 买新能源车概率 <dbl>, 下台车购买计划 <chr>,
## # 获取牌照难度重要性 <dbl>, 充电体验重要性 <dbl>, 续航里程重要性 <dbl>,
## # 汽车价格重要性 <dbl>, 后续维修保养开销重要性 <dbl>, …# 清洗
for(name in names(datas)){
datas[[name]] %<>% ungroup %>% mutate_all(~ifelse(is.na(.x) & .x =="-" ,
NA,
.x))
}
datas_all -> datas[["全部Part合并"]]
dict_excel = list()
for(col in c("knowledge","agree","budget","buygap","check")){
tibble(
"类型" = col,
"指标数值" = !!sym(paste0(col,"_value")),
"指标标签" = !!sym(paste0(col,"_raw"))
) -> dict_excel[[col]]
}
bind_rows(dict_excel) %>% group_by(类型) %>%
do(add_row(.)) -> datas[["数值的标签说明"]]
datas = datas[c(names(datas)[7:8],names(datas)[1:6])]
# datas %>% writeEXCEL("data/EVCars_6个部分全部.xlsx")2 探索性数据分析
在进一步分析用户偏好前,先对原始数据形成一定认知
2.1 拥车现状与购车综合意愿
2.1.1 购车年份与汽车类型的关系
temp = list()
for(col in c("第一台","第二台","第三台")){
data_part_1 %>%
select(作答ID,
contains(paste0(col,"车类型")),
contains(paste0(col, "车购车年份"))) %>%
set_colnames(c("作答ID", "车辆类型","购车年份"))-> temp[[col]]
}
data_part_1 %>%
filter(拥车辆 == 0) %>%
transmute(作答ID,
购车年份 = 2021,
车辆类型 = "目前无车") -> no_car
bind_rows(temp) %>%
filter_at(2:3, all_vars(!is.na(.))) %>%
ggplot() +
aes(x = 购车年份,
fill = 车辆类型) +
geom_bar() +
#scale_fill_brewer(palette = "Greens", direction = 1) +
scale_fill_manual(values = c(get_blues(9)[2],get_greens(3))) +
ylab("购车数") +
ppt_theme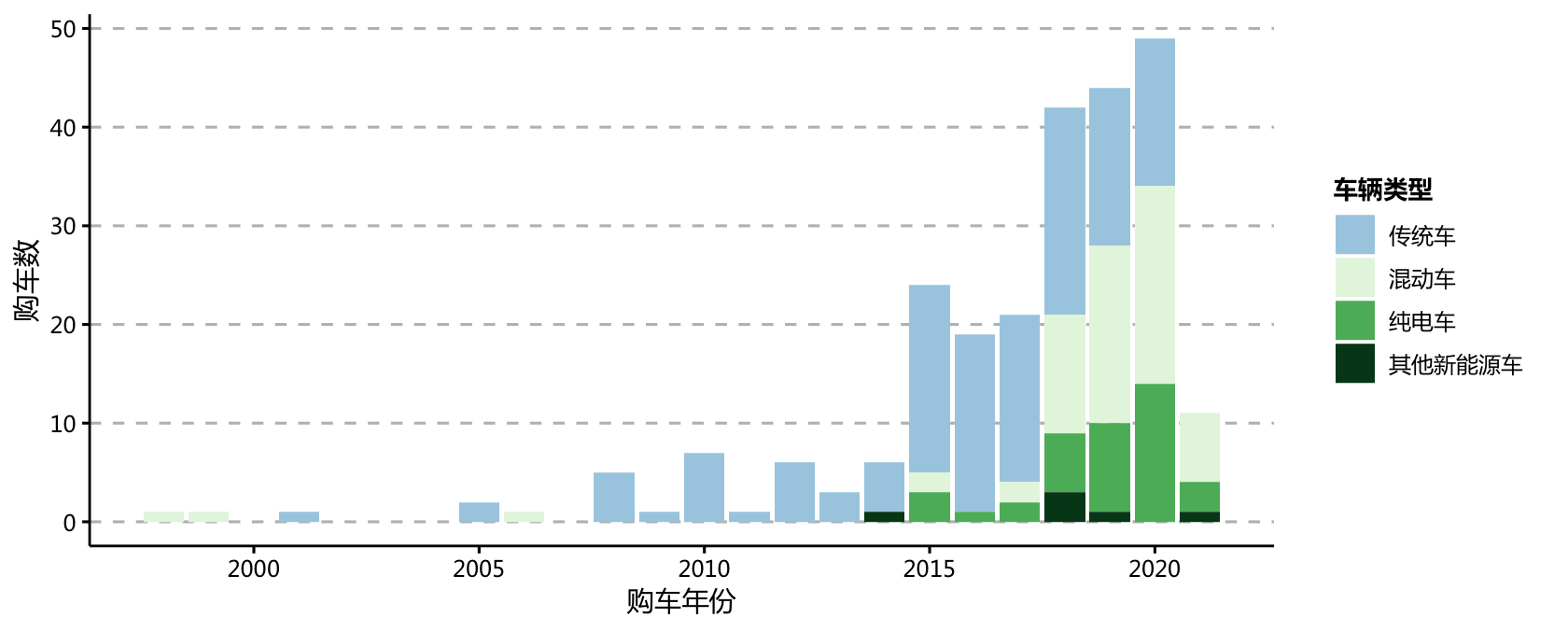
可以看到:
受访者离当前年份越近买车数量越多
2018年开始,受访者(193人)新购入车中电动车比例明显增加,2021年购车的受访者中甚至没有买传统车型的
2.1.2 家庭当前拥有车对下一台车的影响
data_part_1 %>%
filter((!is.na(第一台车类型) & 第一台车类型!="其他新能源车" & 第二台车类型!="其他新能源车" )| 拥车辆 == 1) %>%
mutate_at(c("第一台车类型","第二台车类型"), as.character) %>%
#distinct(第二台车类型)
mutate(第二台车类型 = replace_na(第二台车类型, "暂未购买")) -> foo_1_1
foo_1_1 %>% filter(第二台车类型 != "暂未购买") %>%
group_by(第一台车类型, 第二台车类型) %>%
summarise(num = n()) %>%
pivot_wider(id_cols = 1,
names_from = 第二台车类型,
values_from = num) %>%
fillna_at("混动车",0) -> temp
M = as.table(as.matrix(temp[,-1]))
names(dimnames(M)) = c("家庭第一台车","家庭第二台车")
dimnames(M)$家庭第一台车 <- c("传统车","混动车","纯电车")
labs <- round(prop.table(M,margin=1), 3) * 100
apply(
labs,
2,
function(u) sprintf( "%.1f%%", u )
) -> labs
dimnames(labs)[[1]] <-c("传统车","混动车","纯电车")
names(dimnames(labs)) = c("家庭第一台车","家庭第二台车")
library(vcd)
vcd::mosaic(#~ 第一台车类型 + 第二台车类型 , data = temp,
M,
highlighting_direction = "right",
pop = F,
shade = TRUE,
gp = shading_hcl,
#gp = shading_hcl(HairEyeColor, lty = 1:2),
gp_labels = gpar(fontsize = 9, fontfamily = "Microsoft YaHei"),
gp_varnames = gpar(fontsize = 12, fontfamily = "Microsoft YaHei"))
labeling_cells(text = labs, margin = 0)(M)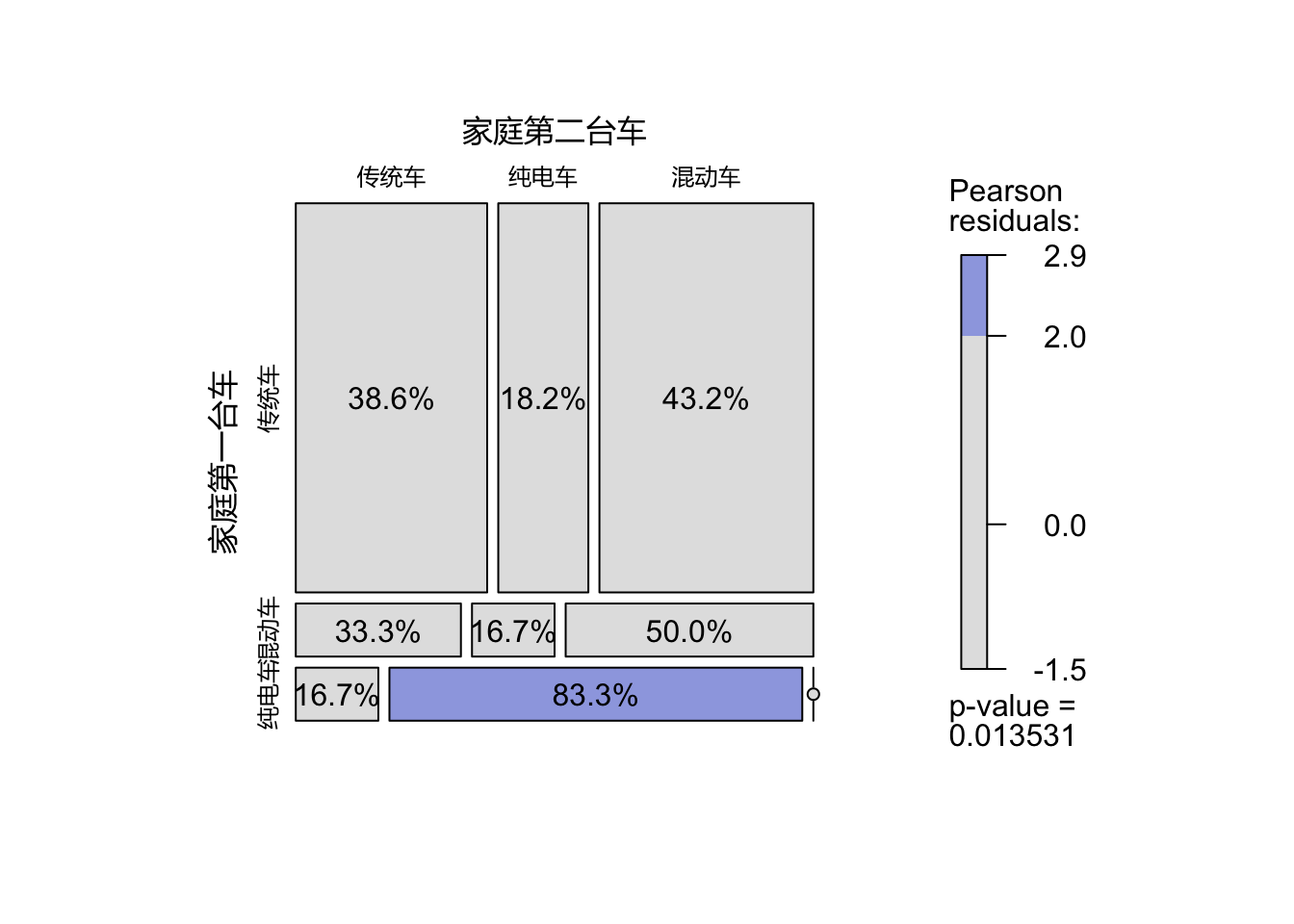
对当前家庭有2台车的56名受访者:
第一台车买传统车的车主有43%下一台尝试了混动,但较少直接购买纯电
第一台车买混动的车主有83%在下一台车都进一步买了纯电
说明新能源车需要一定的“体验时间”来增强消费自信
2.1.3 当前拥车对下一台车的影响
car_info %>%
mutate(已有新能源车 = ifelse(车辆类型 %in% c("混动车", "纯电车","其他新能源车"),1,0)) %>%
group_by(作答ID) %>%
summarise(已有新能源车 = max(已有新能源车)) %>%
transmute(作答ID,
拥车情况 = ifelse(已有新能源车 ==1, "已有新能源车", "只有传统车")) %>%
left_join(datas_all,.) %>%
mutate_at("拥车情况", ~replace_na(.,"无车")) -> foo
vcd::mosaic(~ 拥车情况 + 下台车购买计划, data = foo,
highlighting_direction = "right",
shade = TRUE,
gp = shading_hcl,
#gp = shading_hcl(HairEyeColor, lty = 1:2),
gp_labels = gpar(fontsize = 9, fontfamily = "Microsoft YaHei"),
gp_varnames = gpar(fontsize = 12, fontfamily = "Microsoft YaHei"))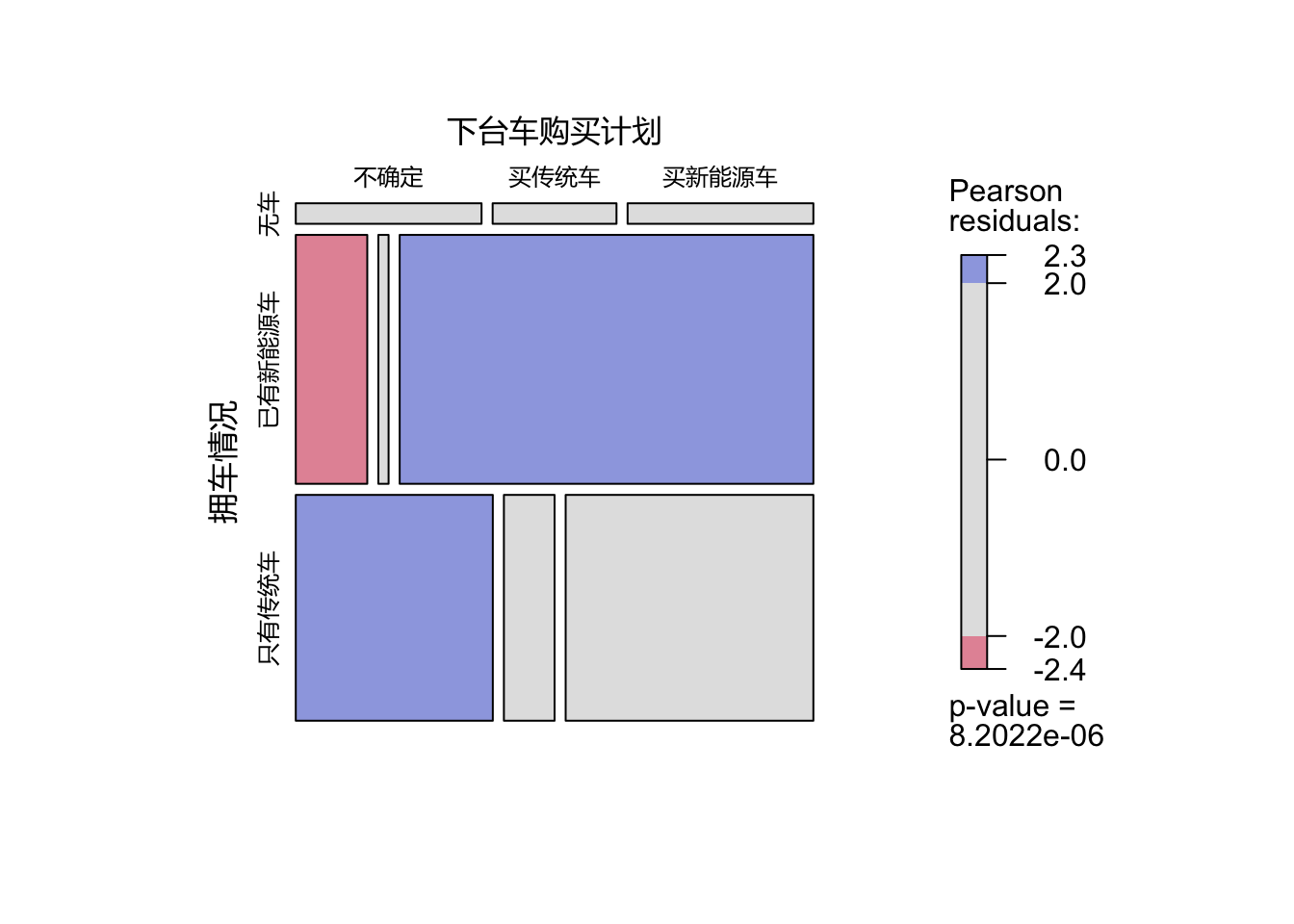
进一步,对所有187名未来7年有购车计划的消费者:
当前开传统车的对下一辆车呈犹豫态度
当前开新能源车的车主很多会继续买新能源车
2.2 车辆外观与性能因素
2.2.1 对汽车百公里加速要求
library(PupillometryR)
data_part_2 %>%
left_join(foo) %>%
ggplot() +
aes(x = 拥车情况, y = 预期百公里加速, fill = 性别) +
geom_flat_violin(
position = position_nudge(x = .2, y = 0),
trim = TRUE,
alpha = .4,
scale = "width") +
geom_point(aes(color = 性别),
position = position_jitter(w = .15, h = 0.9),
size = 1,
alpha = 0.4) +
geom_boxplot(width = .3,
outlier.shape = NA,
alpha = 0.5) +
scale_fill_manual( values =my_pick[-1],na.value = "#5f5f5f") +
scale_color_manual(values =my_pick[-1],na.value = "#5f5f5f") +
unity("秒") +
ppt_theme 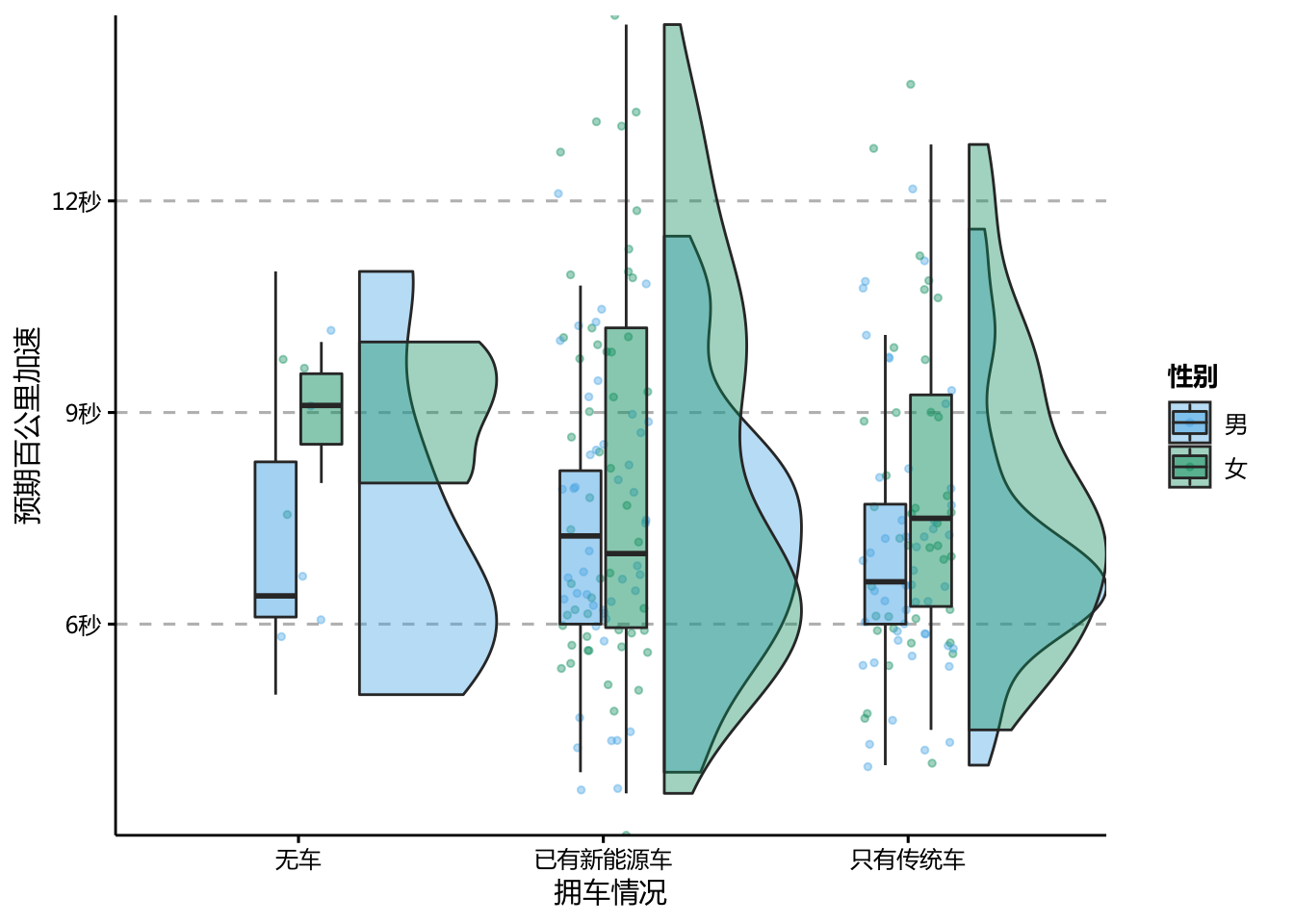
可以看到:
开传统车的车主中更多的男性希望车辆拥有更快的百公里加速
开新能源车的女性对车辆加速度要求更高超过男性,而男性却减少了
2.2.2 对汽车外观和其他功能的要求
data_part_2 %>%
left_join(datas_all %>% select(作答ID, 买新能源车概率,下台车购买计划)) %>%
select(-作答ID) -> foo
fit1 = lm(买新能源车概率 ~ ., data= foo %>% select(-下台车购买计划))
summary(fit1)$coefficients %>%
as_tibble(rownames = "Variable") %>%
arrange(`Pr(>|t|)`)## # A tibble: 13 × 5
## Variable Estimate `Std. Error` `t value` `Pr(>|t|)`
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.533 0.0636 8.39 1.39e-14
## 2 新能源汽车的外观设计更符合我的偏好 0.0431 0.0178 2.42 1.65e- 2
## 3 新能源汽车的起步加速更快 0.0169 0.0120 1.41 1.61e- 1
## 4 电动汽车电池老化快 -0.0195 0.0139 -1.40 1.63e- 1
## 5 `新能源汽车有更先进的驾驶功能(自… 0.0221 0.0163 1.35 1.77e- 1
## 6 新能源汽车的车内噪声更低 0.0188 0.0154 1.22 2.24e- 1
## 7 `新能源汽车的质量(零件不易损坏等… 0.0158 0.0167 0.948 3.44e- 1
## 8 预期百公里加速 0.00421 0.00644 0.653 5.14e- 1
## 9 `电动汽车充电不方便(如公共充电桩… -0.00671 0.0132 -0.509 6.11e- 1
## 10 `新能源汽车驾驶及乘坐舒适度更好(… 0.00721 0.0170 0.426 6.71e- 1
## 11 目前新能源车的续航不足 0.00256 0.0145 0.176 8.60e- 1
## 12 新能源汽车的人机交互系统体验更好 -0.00198 0.0178 -0.111 9.11e- 1
## 13 `新能源汽车的安全性能(耐环境性、… -0.00153 0.0144 -0.106 9.16e- 1vars(c(新能源汽车的外观设计更符合我的偏好,
预期百公里加速,
新能源汽车的起步加速更快,
`新能源汽车有更先进的驾驶功能(自动驾驶及辅助驾驶等)`,下台车购买计划)) -> keep
ggpairs(data = foo %>% select_at(keep) %>%
rename_all(~gsub(INSIDE_PARA,"",.x, perl=TRUE)) %>%
rename_all(~gsub("的","",.x, perl=TRUE)),
mapping = aes(color = 下台车购买计划),
upper = list(continuous = "smooth_loess",
combo = "box",
discrete = "box",
na = "na"),
lower = list(continuous = wrap("cor", size = 4, family = "Microsoft YaHei"),
combo = "box_no_facet",
discrete = "facetbar",
na = "na")) + ppt_theme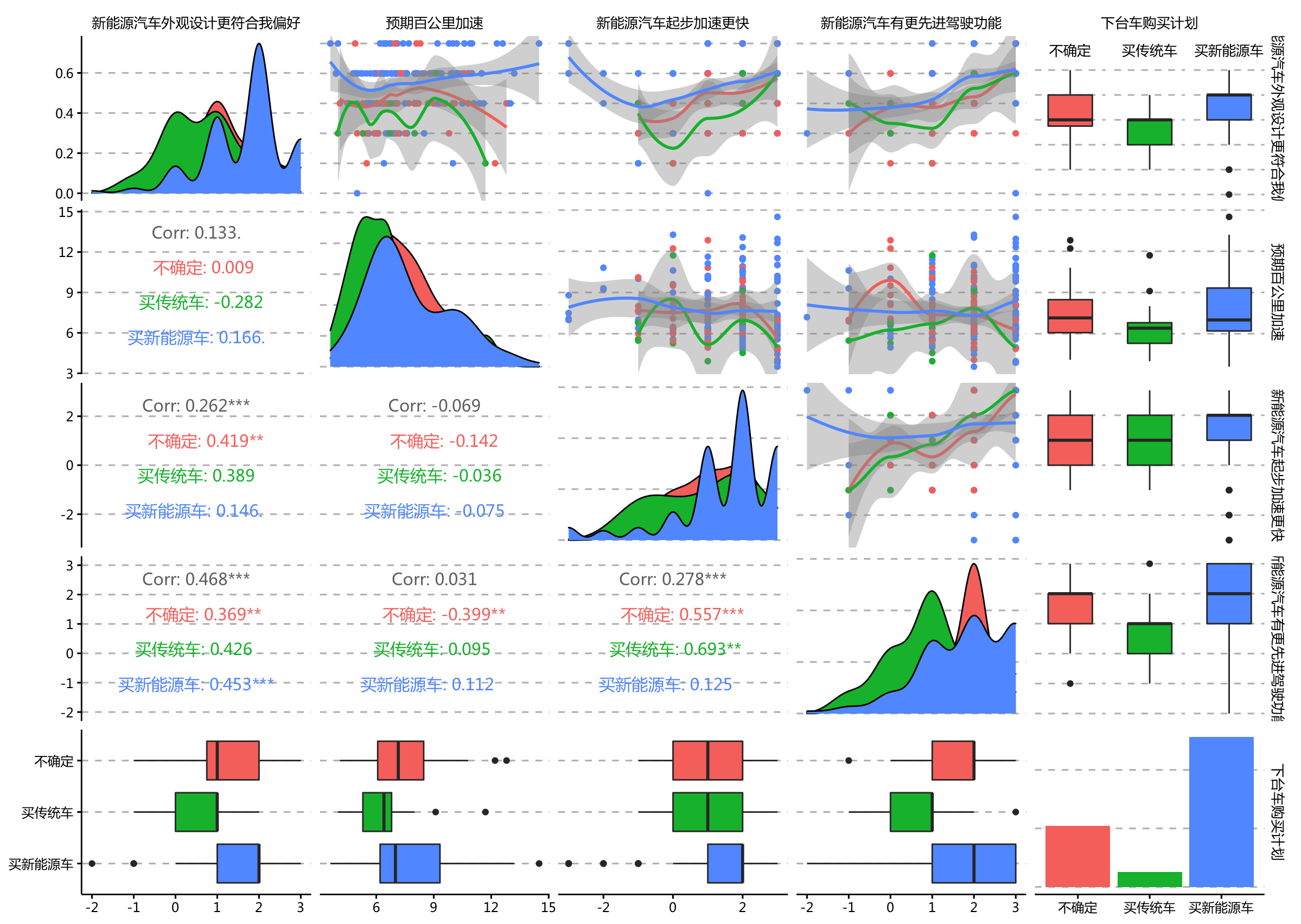
从上图可以看到
下台车基本能确定买新能源车的车主对车的外观、加速认可度更高
下台车买传统车的车主不认为新能源汽车的自动驾驶等功能比传统车好很多
2.3 车辆续航要求与使用场景
2.3.1 通勤时间
read_excel("data/最新全国城市等级划分2020.xlsx", skip=1) %>%
select(城市, 城市等级 = 5) -> city_info
data_part_3 %>%
left_join(datas_all) %>%
left_join(data_part_5 %>% select(作答ID,日常通勤来回路程)) %>%
select(-作答ID) %>%
mutate(城市 = ifelse(城市 == "市辖区", 省份,城市)) %>%
left_join(city_info) %>% select(-c(城市,省份,家庭成员数,年龄,家庭月收入)) %>%
mutate(城市等级 = ifelse(城市等级 %in% c("三线","四线","五线"), "三四线",城市等级)) %>%
mutate(城市等级 = factor(城市等级, c("超一线","一线","二线","三四线"))) %>%
mutate(下台车购买计划 = factor(下台车购买计划, c("买传统车","不确定","买新能源车"))) %>%
arrange(城市等级,下台车购买计划) -> foo
#foo %>% report_na
ggplot(foo) +
aes(x = 下台车购买计划, y = 日常通勤来回路程, fill = 城市等级) +
geom_flat_violin(
position = position_nudge(x = .2, y = 0),
trim = TRUE,
alpha = .4,
scale = "width") +
geom_point(aes(color = 城市等级),
position = position_jitter(w = .15, h = 0.9),
size = 1,
show.legend = F,
alpha = 0.4) +
geom_boxplot(width = .3,
outlier.shape = NA,
alpha = 0.5) +
scale_fill_manual( values =my_pick[-1],na.value = "#5f5f5f") +
scale_color_manual(values =my_pick[-1],na.value = "#5f5f5f") +
unity("km") +
ppt_theme 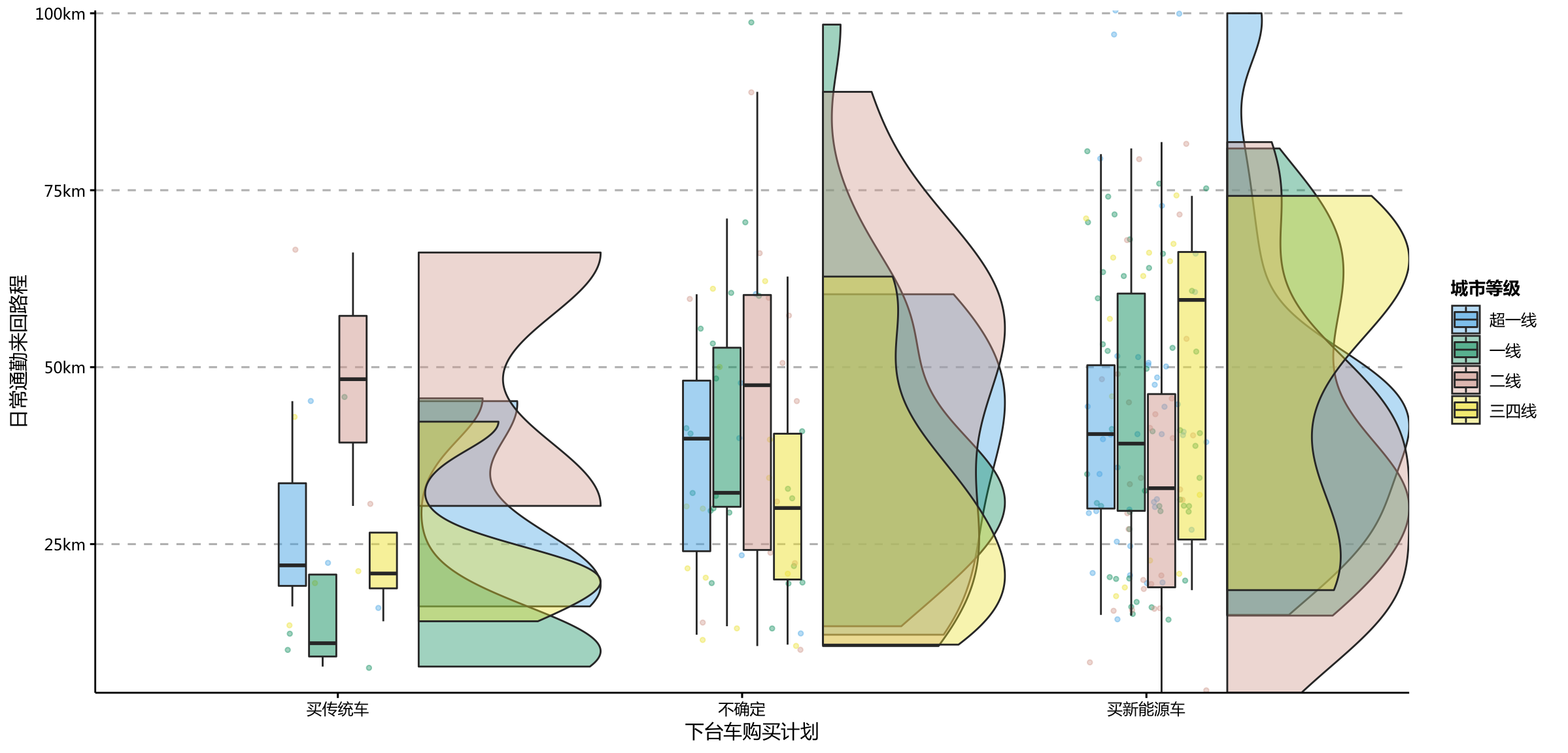
- 受访者中,三四线城市的家庭有许多每天需要的来回通勤时间较长的,但这没有影响他们购买新能源车的计划
2.3.2 续航里程
ggplot(foo) +
aes(x = 下台车购买计划, y = 续航里程要求, fill = 城市等级) +
geom_flat_violin(
position = position_nudge(x = .2, y = 0),
trim = TRUE,
alpha = .4,
scale = "width") +
geom_point(aes(color = 城市等级),
position = position_jitter(w = .15, h = 0.9),
size = 1,
show.legend = F,
alpha = 0.4) +
geom_boxplot(width = .3,
outlier.shape = NA,
alpha = 0.5) +
scale_fill_manual( values =my_pick[-1],na.value = "#5f5f5f") +
scale_color_manual(values =my_pick[-1],na.value = "#5f5f5f") +
unity("km") +
ppt_theme 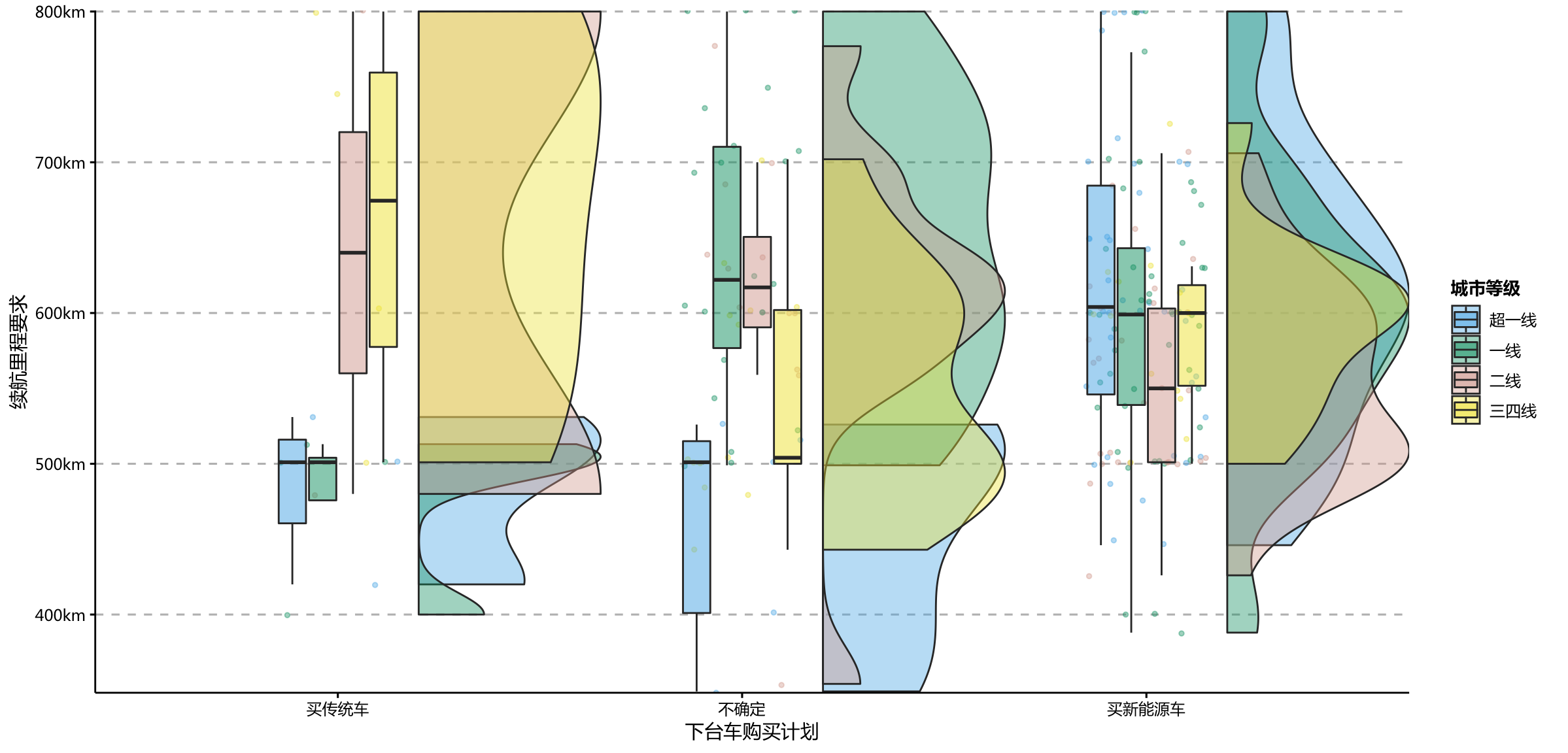
- 超一线城市(北上广深)的车主虽然计划购买新能源车,但是对续航里程的要求平均在600km以上比其他地区的人更高
2.4 车辆品牌与价格因素
2.4.1 消费升级的趋势存在
car_info %>%
group_by(作答ID) %>%
filter(购车年份 == max(购车年份)) %>%
left_join(datas_all) %>%
mutate(下次买车预算 = decode_budget(下次买车预算)) %>%
rename(当前车价位 = 车辆单价) -> foo
vcd::mosaic(~ 当前车价位 + 下次买车预算, data = foo,
highlighting_direction = "right",
shade = TRUE,
gp = shading_hcl,
#margin = c(3,4,2,1),
labeling= labeling_border(rot_labels = c(45,0,0,0),
fontfamily = "Microsoft YaHei",
just_labels = c("left",
"right",
"right",
"right"),
gp_labels = gpar(fontsize = 9, fontfamily = "Microsoft YaHei"),
gp_varnames = gpar(fontsize = 12, fontfamily = "Microsoft YaHei")))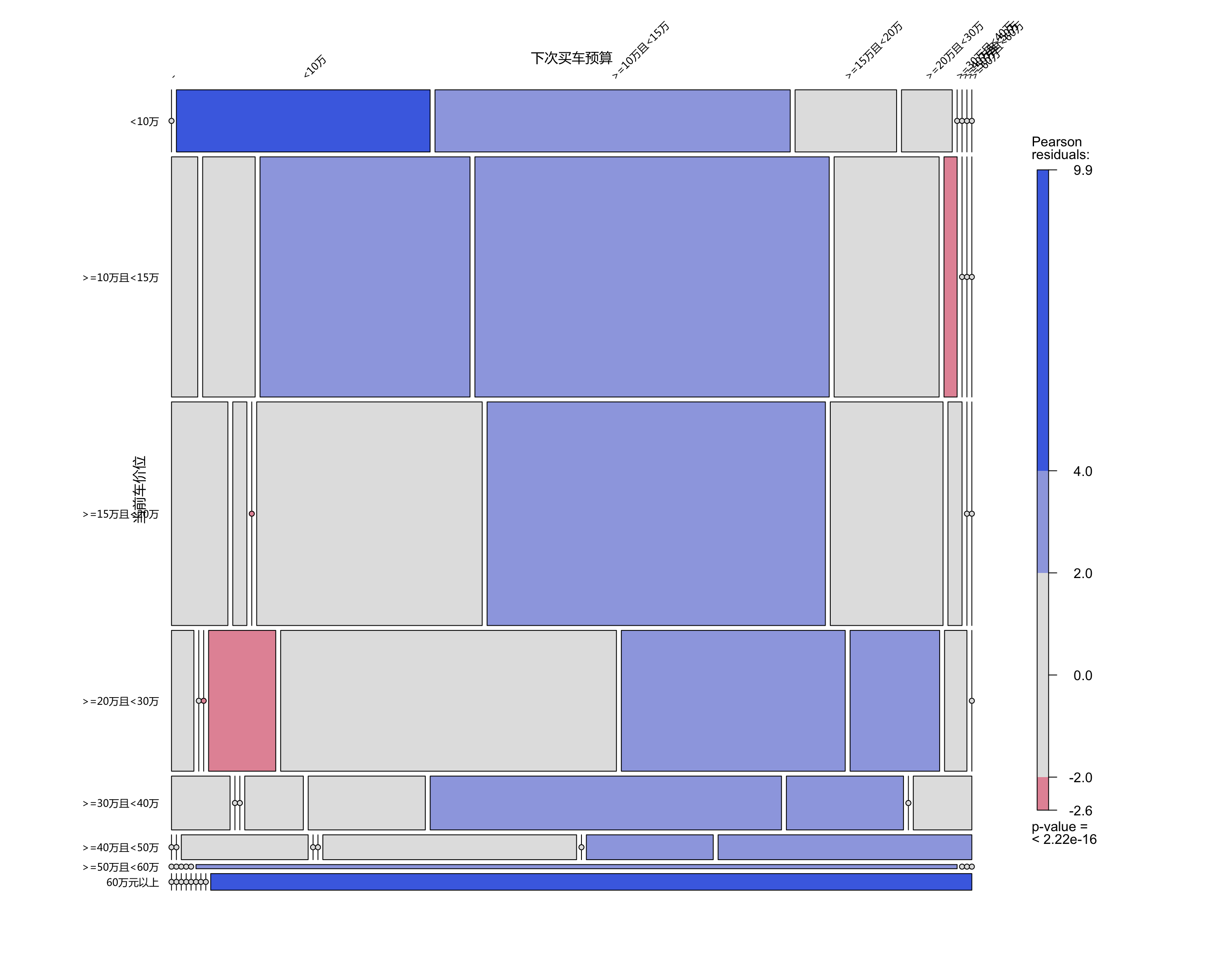
大多数受访者会选择下一台车相较自己当前的车提升一个价格档位,说明存在消费升级的趋势
10~20万元是受访者购车的“甜蜜”区间
3 因子分析与聚类
3.1 相关性探索
data_all %>%
mutate(
新能源车意愿价位 = encode_budget(新能源车意愿价位)
) %>%
select(
# Part-1
了解程度,
拥车辆,
下次买车间隔月数,
下次买车预算,
买新能源车概率,
最后一台车单价,
距上次买车,
#获取牌照难度重要性:售后服务重要性,
# Part 2 性能
新能源汽车的外观设计更符合我的偏好:新能源汽车的起步加速更快,
# Part 3 续航
目前新能源车的续航不足:充电路程时间要求,
# Part 4 价格
新能源车意愿价位:维修保养开销更大,
# Part 5 使用场景
新能源汽车上牌更容易:新能源汽车更加环保, 家庭成员数) -> trainset
trainset %>% select(-买新能源车概率) -> input
input %<>%
rename_all(~gsub(inside_para, "", .x, perl=TRUE))
# 计算相关系数并排序
cor_numVar <- cor(input, use="pairwise.complete.obs") #correlations of all numeric variables
# CorHigh <- c(names(which(apply(cor_sorted, 1, function(x) abs(x)>0.2))))
par(family = "Microsoft YaHei")
res1 <- cor.mtest(input, conf.level = .95)
corrplot(cor_numVar,
order = "hclust",
# 标记
p.mat = res1$p,
insig = "label_sig",
sig.level = c(.001, .01, .05),
pch.cex = .5,
pch.col = "#000000AA",
addrect = 5,
method = "ellipse",
tl.col="#000000DD",
tl.pos = "lt",
tl.srt = 50,
#mar
mar = c(1, 1, 1, 1),
tl.cex = 0.5,
cl.cex = 0.5,
number.cex = 0.4)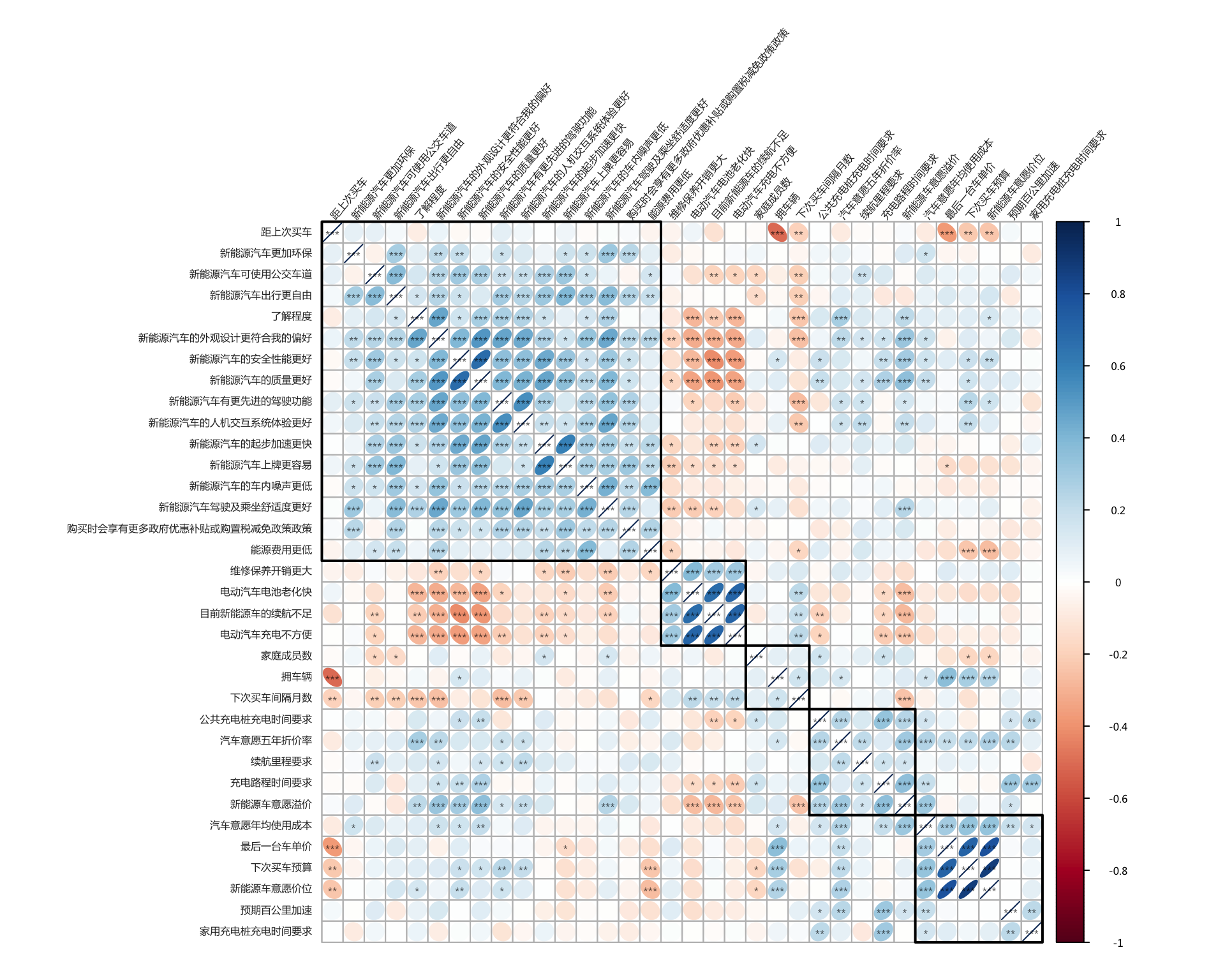
- 许多变量存在很强的自相关性,因此可能需要一定程度的降维处理
3.2 回归
fit <- lm(买新能源车概率 ~ .,
data = trainset)
result <- summary(fit)
result %>% xtable %>% knitr::kable()| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 0.1977259 | 0.1399468 | 1.4128642 | 0.1596625 |
| 了解程度 | 0.0676621 | 0.0204016 | 3.3164996 | 0.0011310 |
| 拥车辆 | 0.0145492 | 0.0286684 | 0.5074999 | 0.6125117 |
| 下次买车间隔月数 | -0.0005400 | 0.0007037 | -0.7673098 | 0.4440425 |
| 下次买车预算 | 0.0000000 | 0.0000002 | -0.2075204 | 0.8358707 |
| 最后一台车单价 | -0.0000004 | 0.0000002 | -1.9728197 | 0.0502610 |
| 距上次买车 | -0.0092701 | 0.0034200 | -2.7105483 | 0.0074599 |
| 新能源汽车的外观设计更符合我的偏好 | 0.0176259 | 0.0186729 | 0.9439306 | 0.3466463 |
新能源汽车有更先进的驾驶功能(自动驾驶及辅助驾驶等) |
0.0142260 | 0.0164982 | 0.8622741 | 0.3898435 |
| 新能源汽车的人机交互系统体验更好 | 0.0001412 | 0.0171528 | 0.0082338 | 0.9934408 |
新能源汽车的安全性能(耐环境性、误操作防护及事故保护等)更好 |
-0.0115366 | 0.0145383 | -0.7935300 | 0.4286592 |
新能源汽车的质量(零件不易损坏等)更好 |
0.0200785 | 0.0163976 | 1.2244774 | 0.2225948 |
| 新能源汽车的车内噪声更低 | 0.0169537 | 0.0153331 | 1.1056899 | 0.2705415 |
新能源汽车驾驶及乘坐舒适度更好(如更平稳等) |
-0.0071110 | 0.0180017 | -0.3950177 | 0.6933626 |
| 新能源汽车的起步加速更快 | 0.0352589 | 0.0136451 | 2.5839921 | 0.0106716 |
| 目前新能源车的续航不足 | -0.0187547 | 0.0141264 | -1.3276372 | 0.1862130 |
电动汽车充电不方便(如公共充电桩太少、家用充电桩不容易装等) |
0.0012257 | 0.0128470 | 0.0954097 | 0.9241103 |
| 电动汽车电池老化快 | 0.0010165 | 0.0139998 | 0.0726078 | 0.9422101 |
| 预期百公里加速 | 0.0056424 | 0.0066001 | 0.8549047 | 0.3938984 |
| 续航里程要求 | 0.0001256 | 0.0001436 | 0.8743090 | 0.3832770 |
| 家用充电桩充电时间要求 | 0.0016010 | 0.0056690 | 0.2824183 | 0.7779924 |
| 公共充电桩充电时间要求 | 0.0005773 | 0.0008043 | 0.7177432 | 0.4739755 |
| 充电路程时间要求 | 0.0006663 | 0.0008088 | 0.8238902 | 0.4112439 |
| 新能源车意愿价位 | 0.0000005 | 0.0000003 | 1.8784149 | 0.0621667 |
| 新能源车意愿溢价 | 0.0032741 | 0.0070517 | 0.4643007 | 0.6430714 |
| 汽车意愿年均使用成本 | 0.0056818 | 0.0161516 | 0.3517827 | 0.7254699 |
| 汽车意愿五年折价率 | -0.0637581 | 0.1136038 | -0.5612320 | 0.5754345 |
| 购买时会享有更多政府优惠补贴或购置税减免政策政策 | 0.0065275 | 0.0196104 | 0.3328589 | 0.7396820 |
| 能源费用更低 | 0.0090811 | 0.0145541 | 0.6239543 | 0.5335574 |
| 维修保养开销更大 | -0.0193547 | 0.0098785 | -1.9592668 | 0.0518415 |
| 新能源汽车上牌更容易 | -0.0321471 | 0.0127917 | -2.5131251 | 0.0129690 |
| 新能源汽车可使用公交车道 | -0.0131938 | 0.0088968 | -1.4829731 | 0.1400735 |
新能源汽车出行更自由(不限行) |
0.0113583 | 0.0112758 | 1.0073150 | 0.3153236 |
| 新能源汽车更加环保 | 0.0302997 | 0.0170961 | 1.7723198 | 0.0782687 |
| 家庭成员数 | -0.0242717 | 0.0117460 | -2.0663714 | 0.0404256 |
- 只有了解程度、距上次买车、以及对新能源汽车的起步加速更快 和 上牌更容易的变量是显著的
3.3 因子分析
3.3.1 确定因子个数
# 确定应提取的因子个数
ev <- eigen(cor(input)) # 获取特征值
ap <- parallel(subject=nrow(input),var=ncol(input),
rep=100,cent=.05) # subject指样本个数,var是指变量个数
nS <- nScree(x=ev$values, aparallel=ap$eigen$qevpea) # 确定探索性因子分析中应保留的因子
plotnScree(nS) # 绘制碎石图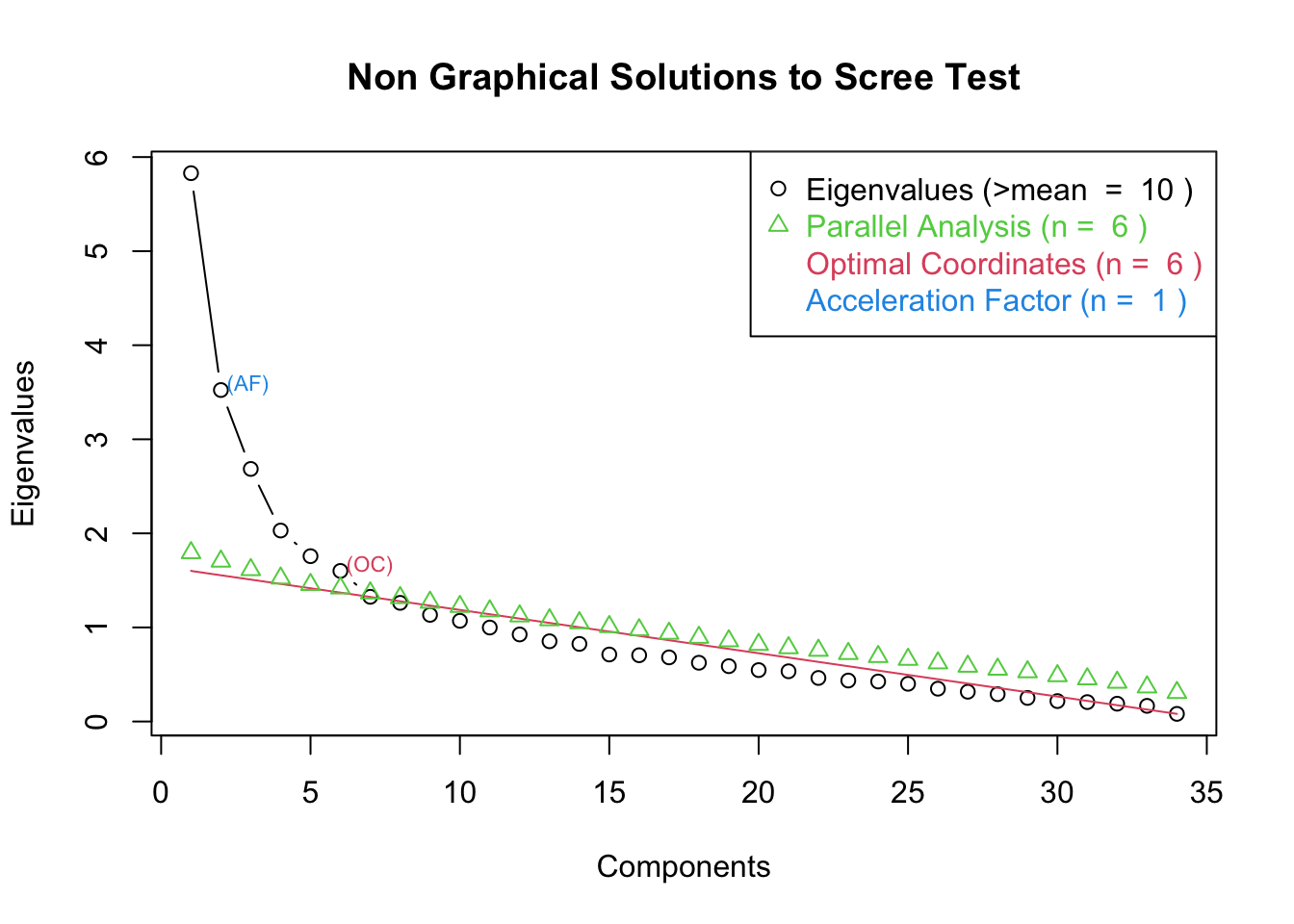
- 从第六个因子开始特征值降低,因此选择6个因子
3.3.2 因子分析
fit <- factanal(input, 6, rotation="varimax", scores="regression")
fit##
## Call:
## factanal(x = input, factors = 6, scores = "regression", rotation = "varimax")
##
## Uniquenesses:
## 了解程度
## 0.712
## 拥车辆
## 0.806
## 下次买车间隔月数
## 0.751
## 下次买车预算
## 0.137
## 最后一台车单价
## 0.253
## 距上次买车
## 0.857
## 新能源汽车的外观设计更符合我的偏好
## 0.391
## 新能源汽车有更先进的驾驶功能
## 0.482
## 新能源汽车的人机交互系统体验更好
## 0.517
## 新能源汽车的安全性能更好
## 0.401
## 新能源汽车的质量更好
## 0.246
## 新能源汽车的车内噪声更低
## 0.707
## 新能源汽车驾驶及乘坐舒适度更好
## 0.603
## 新能源汽车的起步加速更快
## 0.453
## 目前新能源车的续航不足
## 0.300
## 电动汽车充电不方便
## 0.266
## 电动汽车电池老化快
## 0.304
## 预期百公里加速
## 0.831
## 续航里程要求
## 0.907
## 家用充电桩充电时间要求
## 0.876
## 公共充电桩充电时间要求
## 0.657
## 充电路程时间要求
## 0.641
## 新能源车意愿价位
## 0.082
## 新能源车意愿溢价
## 0.617
## 汽车意愿年均使用成本
## 0.744
## 汽车意愿五年折价率
## 0.718
## 购买时会享有更多政府优惠补贴或购置税减免政策政策
## 0.814
## 能源费用更低
## 0.761
## 维修保养开销更大
## 0.801
## 新能源汽车上牌更容易
## 0.405
## 新能源汽车可使用公交车道
## 0.817
## 新能源汽车出行更自由
## 0.430
## 新能源汽车更加环保
## 0.845
## 家庭成员数
## 0.880
##
## Loadings:
## Factor1 Factor2 Factor3
## 了解程度 0.115 -0.245 0.243
## 拥车辆 0.340 0.108
## 下次买车间隔月数 0.257 -0.132
## 下次买车预算 0.867 -0.124
## 最后一台车单价 0.858
## 距上次买车 -0.319
## 新能源汽车的外观设计更符合我的偏好 -0.254 0.331
## 新能源汽车有更先进的驾驶功能 0.260
## 新能源汽车的人机交互系统体验更好 0.267
## 新能源汽车的安全性能更好 0.152 -0.273 0.161
## 新能源汽车的质量更好 -0.254 0.138
## 新能源汽车的车内噪声更低 0.479
## 新能源汽车驾驶及乘坐舒适度更好 -0.122 0.456
## 新能源汽车的起步加速更快 -0.121 0.436
## 目前新能源车的续航不足 0.795
## 电动汽车充电不方便 0.833
## 电动汽车电池老化快 0.808
## 预期百公里加速
## 续航里程要求 0.152
## 家用充电桩充电时间要求 0.135
## 公共充电桩充电时间要求 -0.120
## 充电路程时间要求 -0.133
## 新能源车意愿价位 0.943
## 新能源车意愿溢价 -0.184
## 汽车意愿年均使用成本 0.361
## 汽车意愿五年折价率 0.270 0.117
## 购买时会享有更多政府优惠补贴或购置税减免政策政策 0.337
## 能源费用更低 -0.236 0.416
## 维修保养开销更大 0.108 0.402 -0.128
## 新能源汽车上牌更容易 -0.119 -0.149 0.529
## 新能源汽车可使用公交车道 -0.158 0.325
## 新能源汽车出行更自由 0.159 0.715
## 新能源汽车更加环保 0.355
## 家庭成员数 -0.162
## Factor4 Factor5 Factor6
## 了解程度 0.327 0.213
## 拥车辆 0.225 0.114
## 下次买车间隔月数 -0.364 0.116 0.138
## 下次买车预算 0.283 -0.118
## 最后一台车单价
## 距上次买车 0.156 -0.118
## 新能源汽车的外观设计更符合我的偏好 0.615 0.210 0.113
## 新能源汽车有更先进的驾驶功能 0.630 -0.103 0.164
## 新能源汽车的人机交互系统体验更好 0.612 0.183
## 新能源汽车的安全性能更好 0.287 0.180 0.600
## 新能源汽车的质量更好 0.417 0.277 0.644
## 新能源汽车的车内噪声更低 0.189 0.122
## 新能源汽车驾驶及乘坐舒适度更好 0.371 0.105 0.153
## 新能源汽车的起步加速更快 0.583
## 目前新能源车的续航不足 -0.107 -0.166 -0.164
## 电动汽车充电不方便 -0.117 -0.110 -0.107
## 电动汽车电池老化快 -0.151
## 预期百公里加速 0.382
## 续航里程要求 0.142 0.192
## 家用充电桩充电时间要求 -0.151 0.287
## 公共充电桩充电时间要求 -0.109 0.555
## 充电路程时间要求 0.575 0.102
## 新能源车意愿价位 0.140
## 新能源车意愿溢价 0.346 0.466 0.101
## 汽车意愿年均使用成本 0.155 0.314
## 汽车意愿五年折价率 0.212 0.379
## 购买时会享有更多政府优惠补贴或购置税减免政策政策 0.196 0.154
## 能源费用更低
## 维修保养开销更大
## 新能源汽车上牌更容易 -0.136 0.504
## 新能源汽车可使用公交车道 0.203
## 新能源汽车出行更自由 -0.159
## 新能源汽车更加环保 0.154
## 家庭成员数 0.289
##
## Factor1 Factor2 Factor3 Factor4 Factor5 Factor6
## SS loadings 3.041 2.661 2.389 2.334 1.875 1.690
## Proportion Var 0.089 0.078 0.070 0.069 0.055 0.050
## Cumulative Var 0.089 0.168 0.238 0.307 0.362 0.411
##
## Test of the hypothesis that 6 factors are sufficient.
## The chi square statistic is 606.66 on 372 degrees of freedom.
## The p-value is 1.61e-13input %>% cbind(fit$scores) %>%
select(Factor1:Factor6) -> input_2
loadings_mat <- as.data.frame(matrix(nrow = 34, ncol =6))
loadings_mat$Variable <- colnames(input)
for (i in 1:6) {
for (j in 1:34) {
loadings_mat[j, i] <- fit$loadings[j, i]
}
}
loadings_mat %>% gather("Factor", "Value", 1:6) %>%
ggplot(aes(Variable, abs(Value), fill=Value)) +
facet_wrap(~ Factor, nrow=1) +
geom_bar(stat="identity") +
coord_flip() +
xlab("") + ylab("") +
scale_fill_gradient2(name = "Loading",
high = "blue", mid = "white", low = "red",
midpoint=0, guide=F) + ppt_theme + only_x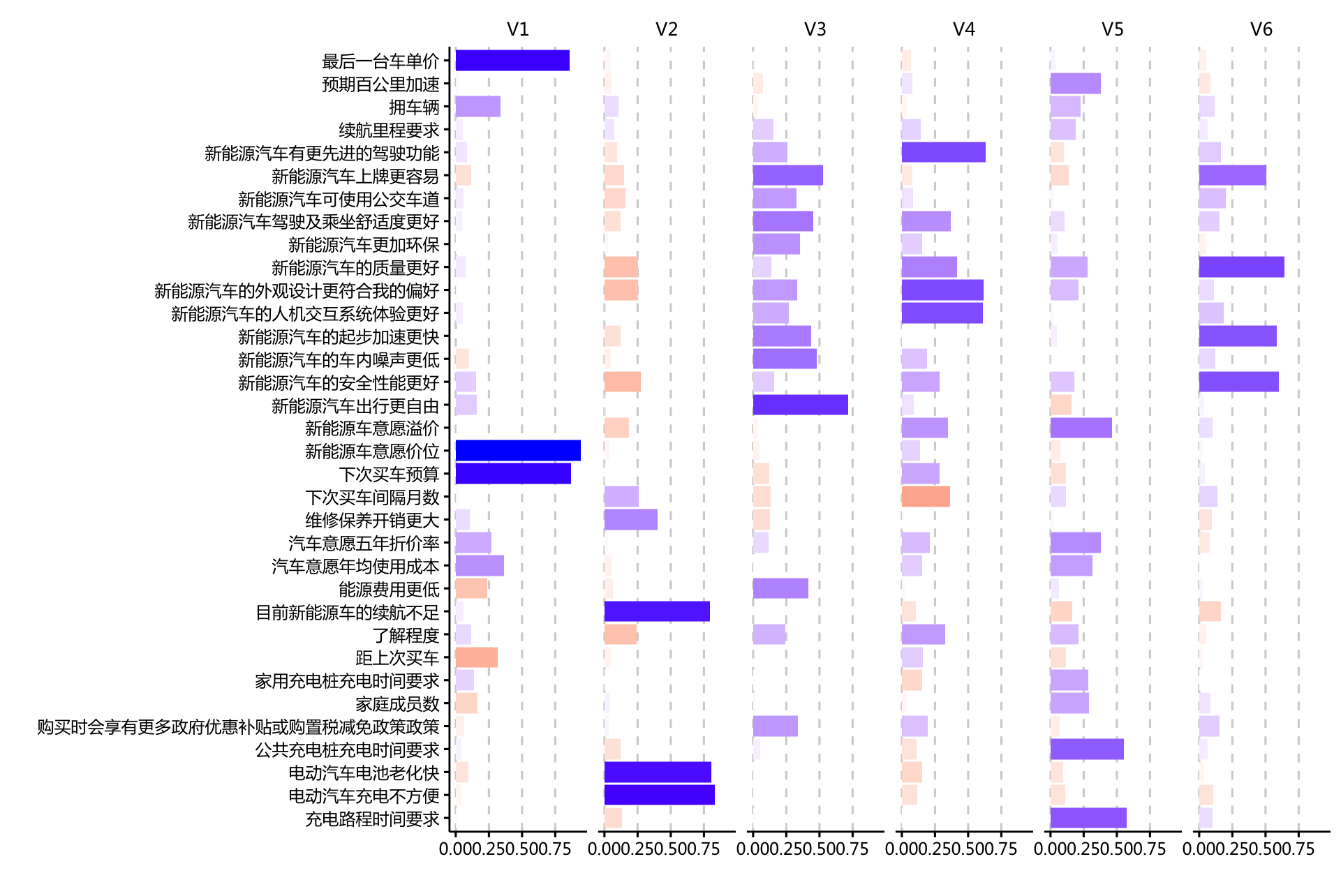
- 在6个因子中,前两个较为显著,进一步两两作图判断:
3.3.3 因子定义
3.3.3.1 因子1、2
load <- fit$loadings[,1:2]
as_tibble(load, rownames = "变量") %>%
ggplot(aes(
x = Factor1,
y = Factor2,
label = 变量
)) +
#geom_text(family = "Microsoft YaHei",
# size = 3) +
geom_point() +
geom_text_repel(family = "Microsoft YaHei",
size = 4, min.segment.length = unit(0.4, "lines")) +
ppt_theme
- 因子1:消费能力
- 因子2:续航需求
3.3.3.2 因子3、4
load <- fit$loadings[,3:4]
as_tibble(load, rownames = "变量") %>%
ggplot(aes(
x = Factor3,
y = Factor4,
label = 变量
)) +
#geom_text(family = "Microsoft YaHei",
# size = 3) +
geom_point() +
geom_text_repel(family = "Microsoft YaHei",
size = 4, min.segment.length = unit(0.4, "lines")) +
ppt_theme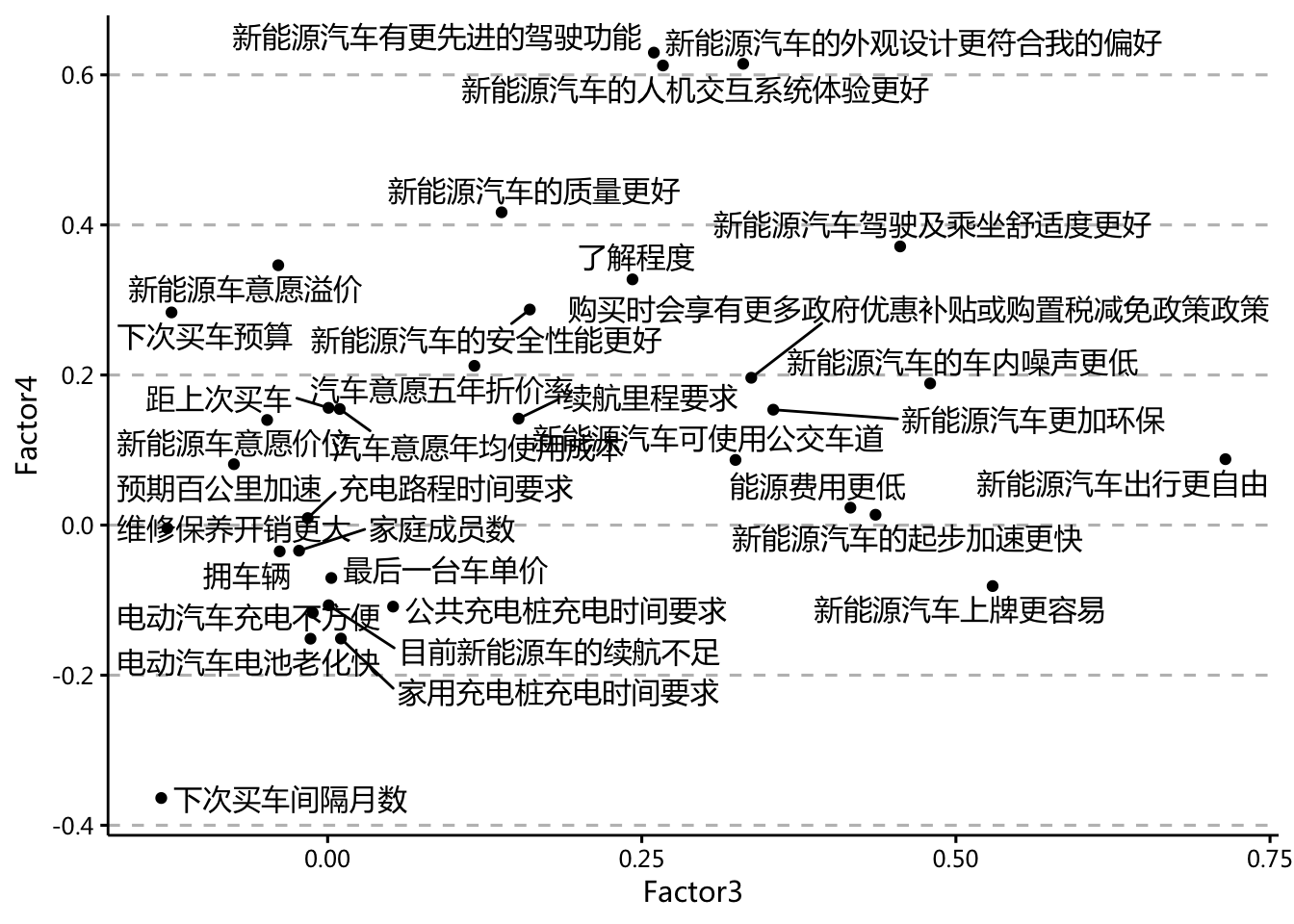
- 因子3:出行方便
- 因子4:性能先进
3.3.3.3 因子5、6
load <- fit$loadings[,5:6]
as_tibble(load, rownames = "变量") %>%
ggplot(aes(
x = Factor5,
y = Factor6,
label = 变量
)) +
#geom_text(family = "Microsoft YaHei",
# size = 3) +
geom_point() +
geom_text_repel(family = "Microsoft YaHei",
size = 4, min.segment.length = unit(0.4, "lines")) +
ppt_theme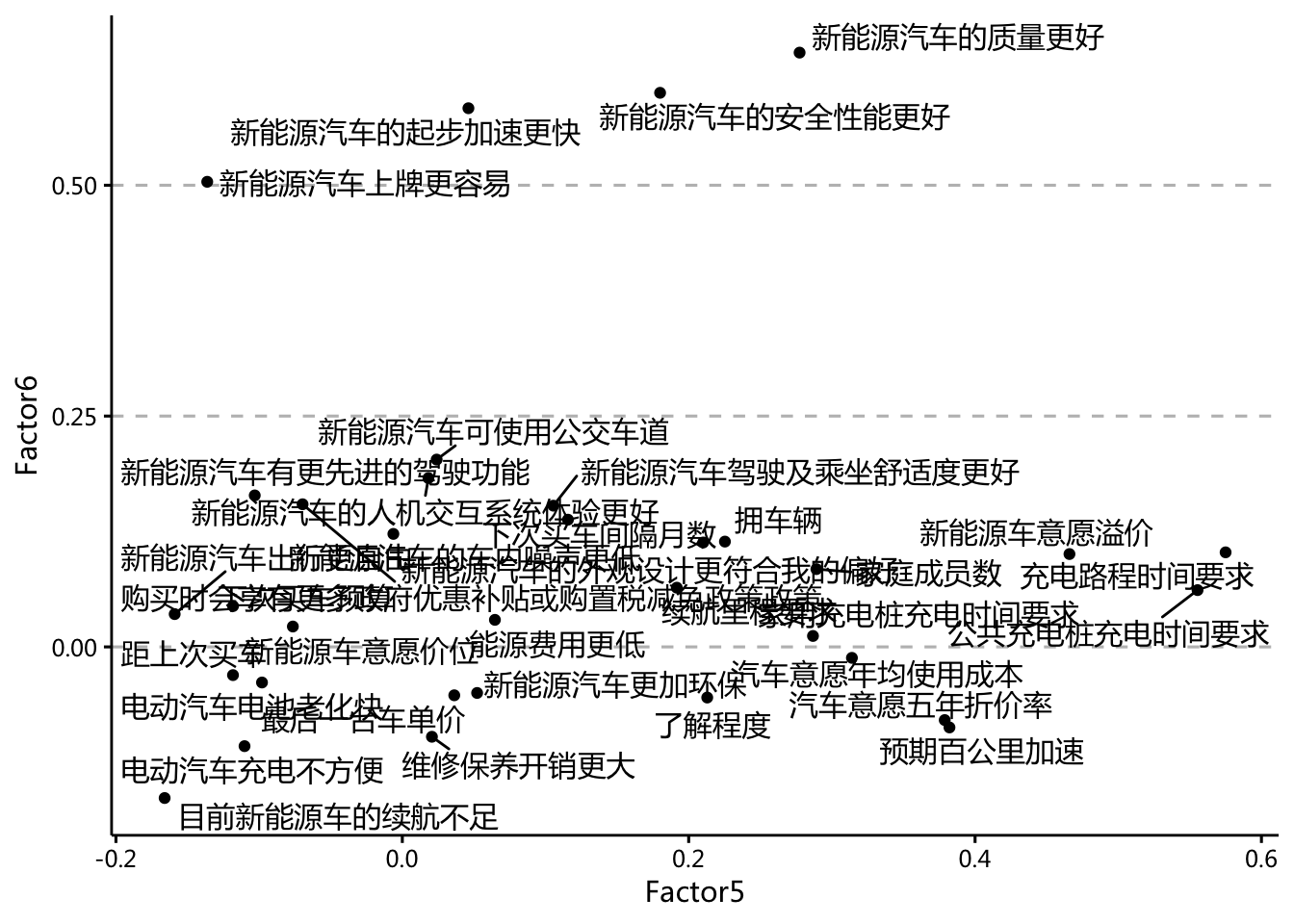
- 因子5和因子6混合的因素过多,比较难确定其作用
3.4 聚类分析
3.4.1 选择需要聚类的数
bss <- numeric()
wss <- numeric()
# Run the algorithm for different values of k
set.seed(1234)
for(i in 1:10){
# For each k, calculate betweenss and tot.withinss
bss[i] <- kmeans(input_2, centers=i)$betweenss
wss[i] <- kmeans(input_2, centers=i)$tot.withinss
}
# Between-cluster sum of squares vs Choice of k
p3 <- qplot(1:10, bss, geom=c("point", "line"),
xlab="Number of clusters", ylab="Between-cluster sum of squares") +
scale_x_continuous(breaks=seq(0, 10, 1)) +
theme_bw()
# Total within-cluster sum of squares vs Choice of k
p4 <- qplot(1:10, wss, geom=c("point", "line"),
xlab="Number of clusters", ylab="Total within-cluster sum of squares") +
scale_x_continuous(breaks=seq(0, 10, 1)) +
theme_bw()
# Subplot
grid.arrange(p3, p4, ncol=2)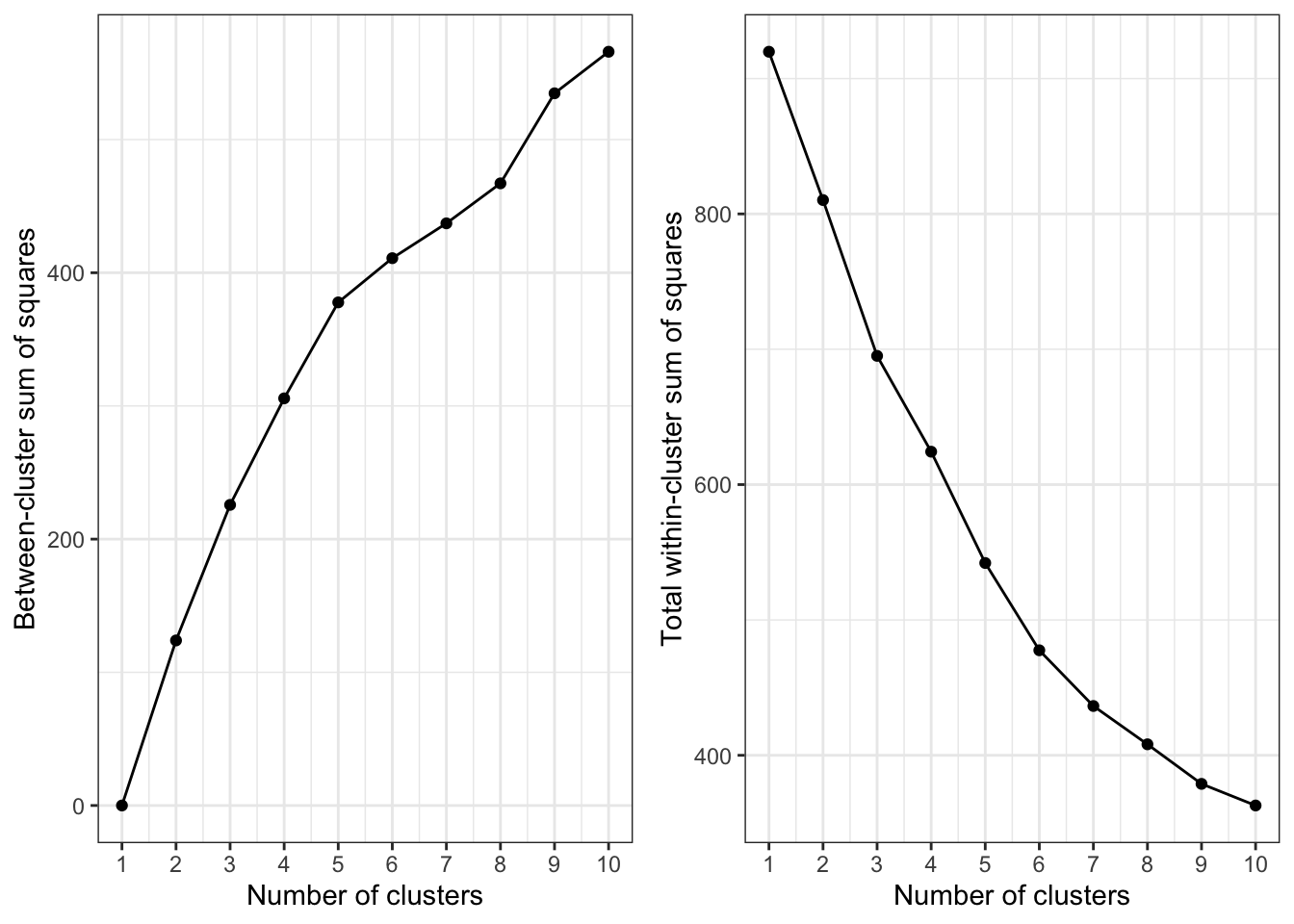
- 从最小化组内离差平方和最大化组间离差平方和的角度,似乎选择1~5都是合理的
fit2 <- kmeans(input, centers = 2, nstart = 25)
fit3 <- kmeans(input, centers = 3, nstart = 25)
fit4 <- kmeans(input, centers = 4, nstart = 25)
fit5 <- kmeans(input, centers = 5, nstart = 25)
# plots to compare
p1 <- fviz_cluster(fit2, geom = "point", data = input) + ggtitle("k = 2")
p2 <- fviz_cluster(fit3, geom = "point", data = input) + ggtitle("k = 3")
p3 <- fviz_cluster(fit4, geom = "point", data = input) + ggtitle("k = 4")
p4 <- fviz_cluster(fit5, geom = "point", data = input) + ggtitle("k = 5")
library(gridExtra)
grid.arrange(p1, p2, p3, p4, nrow = 2)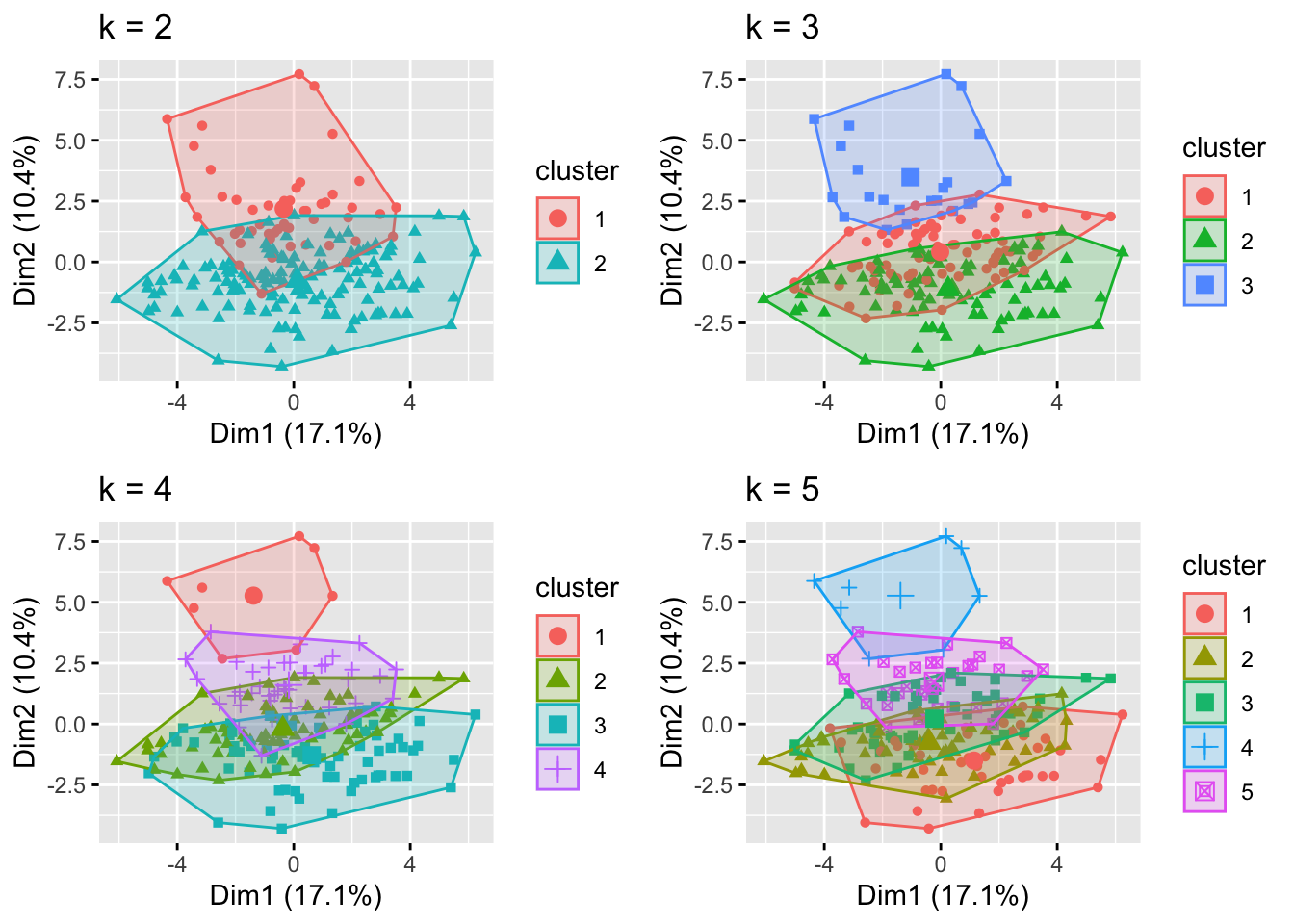
- 将前两个维度可视化后发现,聚为4和5类时,位于两维度均值附近的样本点比较难区分开
fviz_nbclust(input, kmeans, method = "silhouette")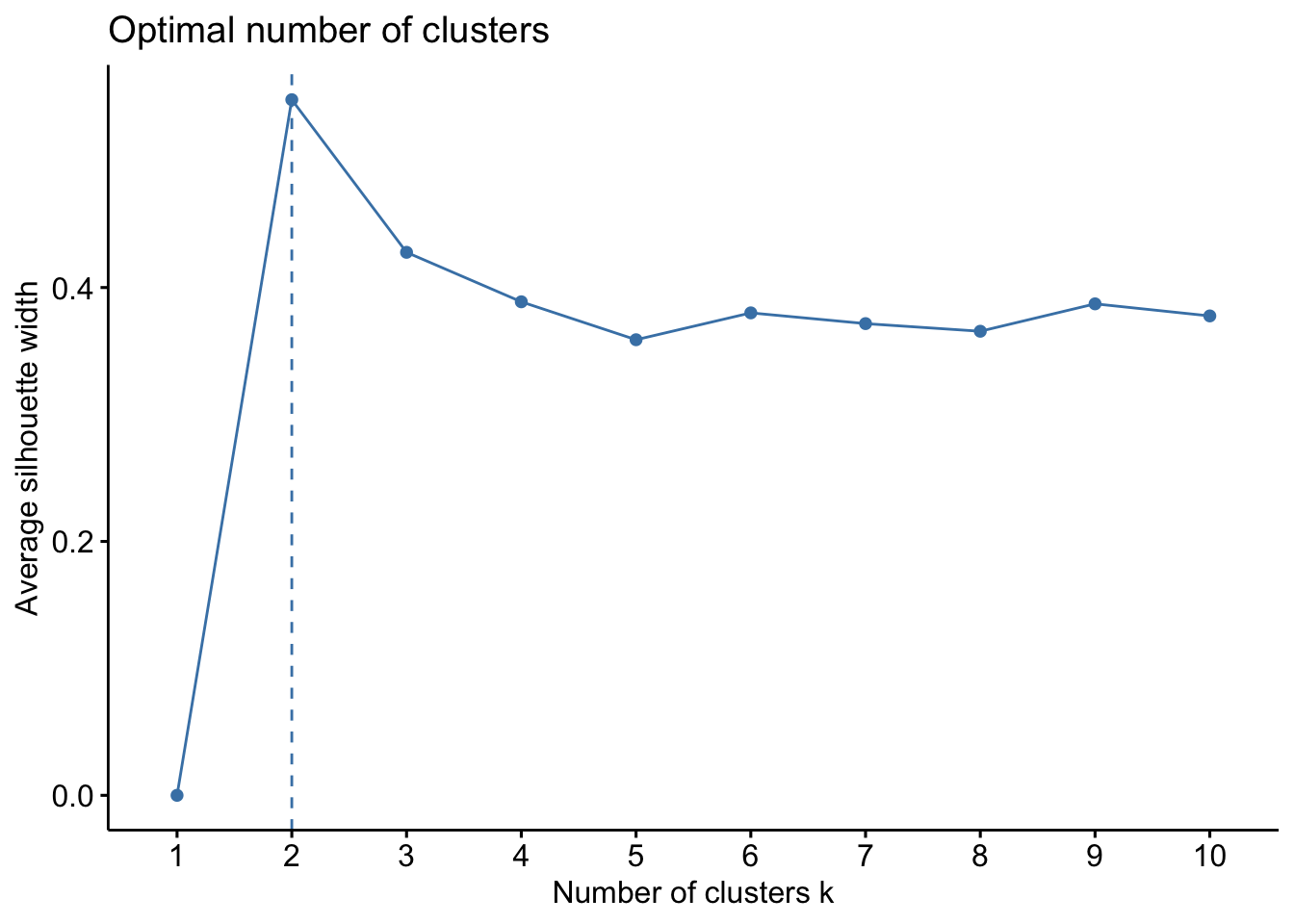
使用
silhouette方法判断时则明确给出了2类作为聚类数量,考虑到受访者中已经有了众多的新能源车车主,且整体愿意下台车购买新能源车概率在72.3%,因此已经是很好的用户群target了,从中再挖掘出1类细分用户也是足够的。原因猜测:对新能源车不感兴趣的话不会填写这份问卷
3.5 对聚类结果T检验
trainset %>%
mutate(cluster = factor(fit2$cluster)) -> input_glm_k2
trainset %>%
mutate(cluster = factor(fit2$cluster)) -> input_glm_k3
data_all %>%
mutate(cluster = fit3$cluster) -> result_k3
data_all %>%
mutate(cluster = fit2$cluster) -> result_k2# T-test
# Perform a t-test between groups
stat.test <- compare_means(
买新能源车概率 ~ cluster,
data = result_k3,
method = "t.test"
)
stat.test <- stat.test %>%
mutate(y.position = c(1.1,1.2,1.3))
p <- ggboxplot(result_k3, x = "cluster", y = "买新能源车概率")
p + stat_pvalue_manual(stat.test, label = "p = {p.adj} {p.signif}") -> p1
stat.test <- compare_means(
买新能源车概率 ~ cluster,
data = result_k2,
method = "t.test"
)
stat.test <- stat.test %>%
mutate(y.position = c(1.1))
p <- ggboxplot(result_k2, x = "cluster", y = "买新能源车概率")
p + stat_pvalue_manual(stat.test, label = "p = {p.adj} {p.signif}") -> p2
(p1 + ppt_theme) + (p2 + ppt_theme)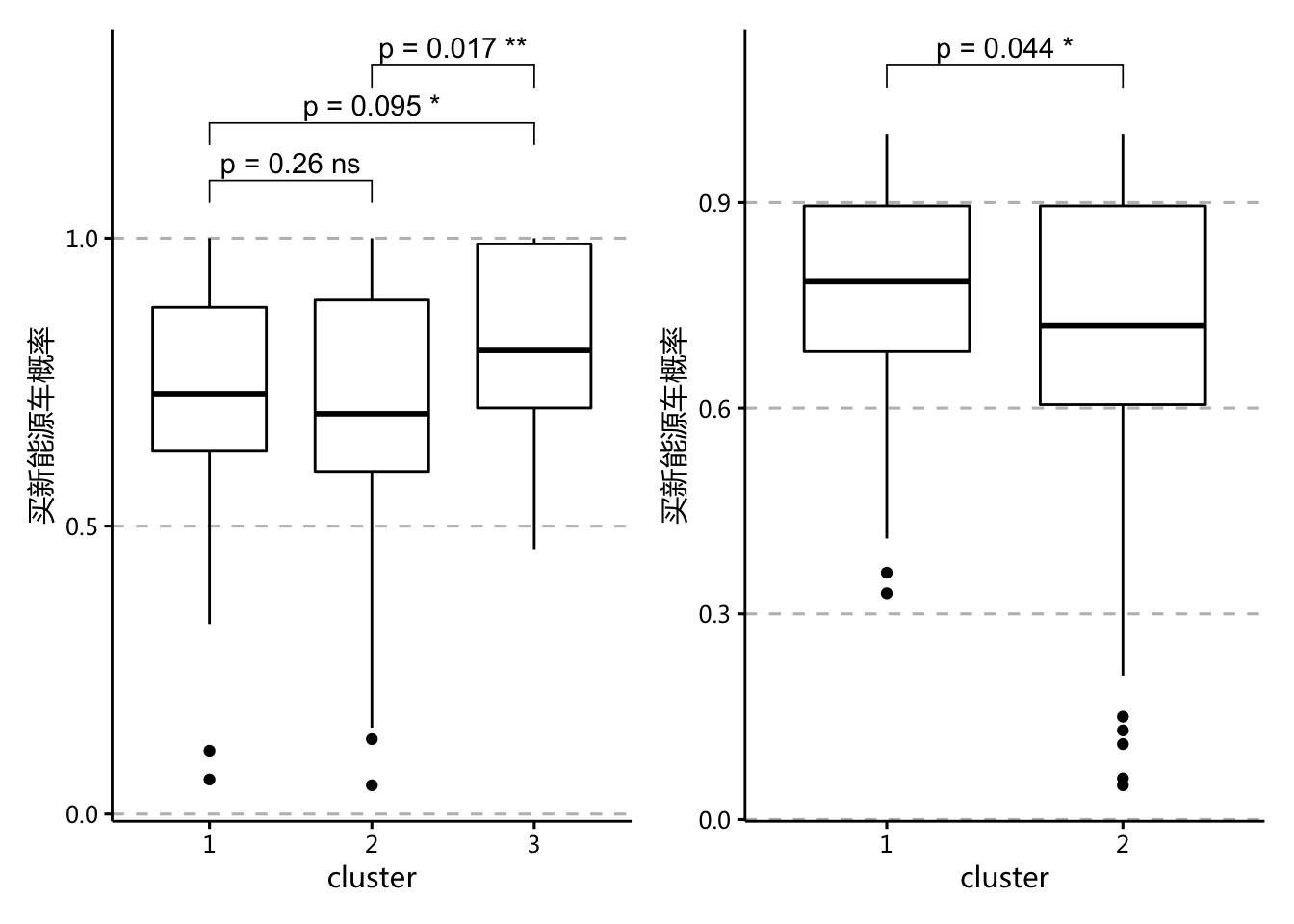
- 从T检验中也可以看到,右图聚为2类时第一类用户显著有更高的购买意愿,而聚为3类时虽然第三类与1、2都有显著差距,但是1和2之间区别并不明显,综合考虑选择聚为2类
4 目标客群的用户画像与营销方案
result <- result_k2 %>% mutate(cluster = factor(as.character(cluster),
level = c("1","2"),
label = c("第一类","第二类")))4.1 用户画像
# 除了家庭月收入、和人数
read_excel("data/最新全国城市等级划分2020.xlsx", skip=1) %>%
select(城市, 城市等级 = 5) -> city_info
result %>%
select(cluster) %>%
cbind(data_part_6 %>% ungroup %>% select(性别:职业)) %>%
as_tibble %>%
mutate(城市 = ifelse(城市 == "市辖区", 省份,城市)) %>%
left_join(city_info) %>% select(-c(城市,省份,家庭成员数,年龄,家庭月收入)) %>%
mutate(城市等级 = factor(城市等级, c("超一线","一线","二线","三线","四线","五线"))) %>%
arrange(城市等级) %>%
pivot_longer(性别:城市等级,names_to = "指标", values_to = "指标值") %>%
group_by(指标,cluster, 指标值) %>%
summarise(占比 = n()) %>%
group_by(指标, cluster) %>%
mutate(占比 = 占比 / sum(占比,na.rm=T)) %>%
ggplot() +
aes(x = `指标值`, fill = cluster, y = `占比`) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_manual(values = rev(get_blues(2))) +
ppt_theme +
scale_y_continuous(expand = c(0, 0),
labels = scales::percent,
breaks = scales::breaks_pretty(5)) +
only_x +
coord_flip() +
facet_wrap(指标~. ,scales="free", ncol = 2)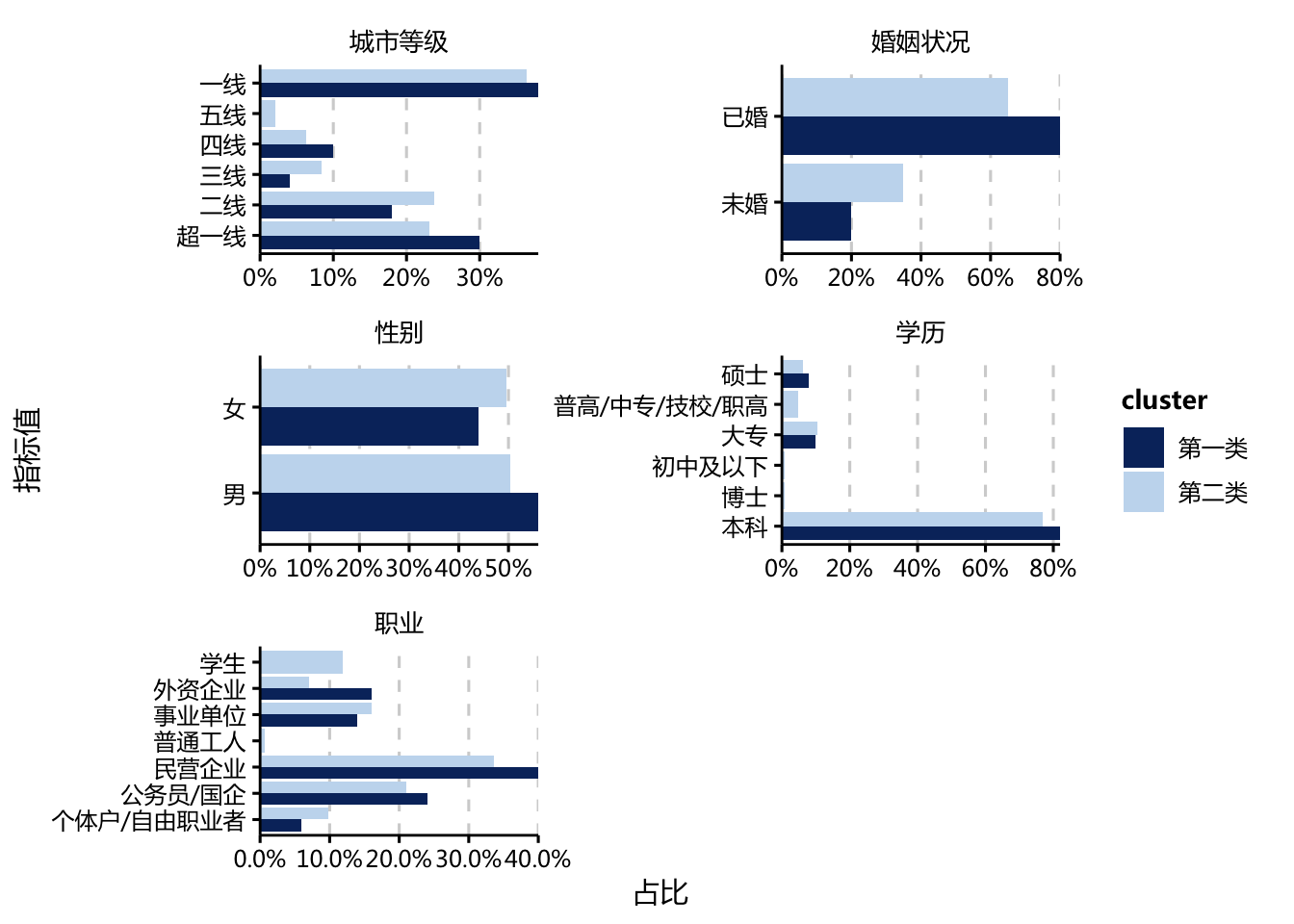
- 可以看到目标的第一类群体更多在北上广深、学历更高、在民营企业或国企工作较多(且不是学生)、已婚
result %>%
select(cluster) %>%
cbind(data_part_6 %>% ungroup %>% select(性别:职业)) %>%
as_tibble %>%
select(cluster,家庭成员数,年龄,家庭月收入) %>%
pivot_longer(家庭成员数:家庭月收入) %>%
ggplot() +
aes(x = name, y = value, fill = cluster) +
geom_flat_violin(
position = position_nudge(x = .2, y = 0),
trim = TRUE,
alpha = .4,
scale = "width") +
geom_point(aes(color = cluster),
position = position_jitter(w = .15, h = 0.9),
size = 1,
alpha = 0.4) +
geom_boxplot(width = .3,
outlier.shape = NA,
alpha = 0.5) +
scale_fill_manual( values =my_pick[-1],na.value = "#5f5f5f") +
scale_color_manual(values =my_pick[-1],na.value = "#5f5f5f") +
bigy +
ppt_theme +
ylab("") +
xlab("") +
facet_wrap(name~.,scale = "free")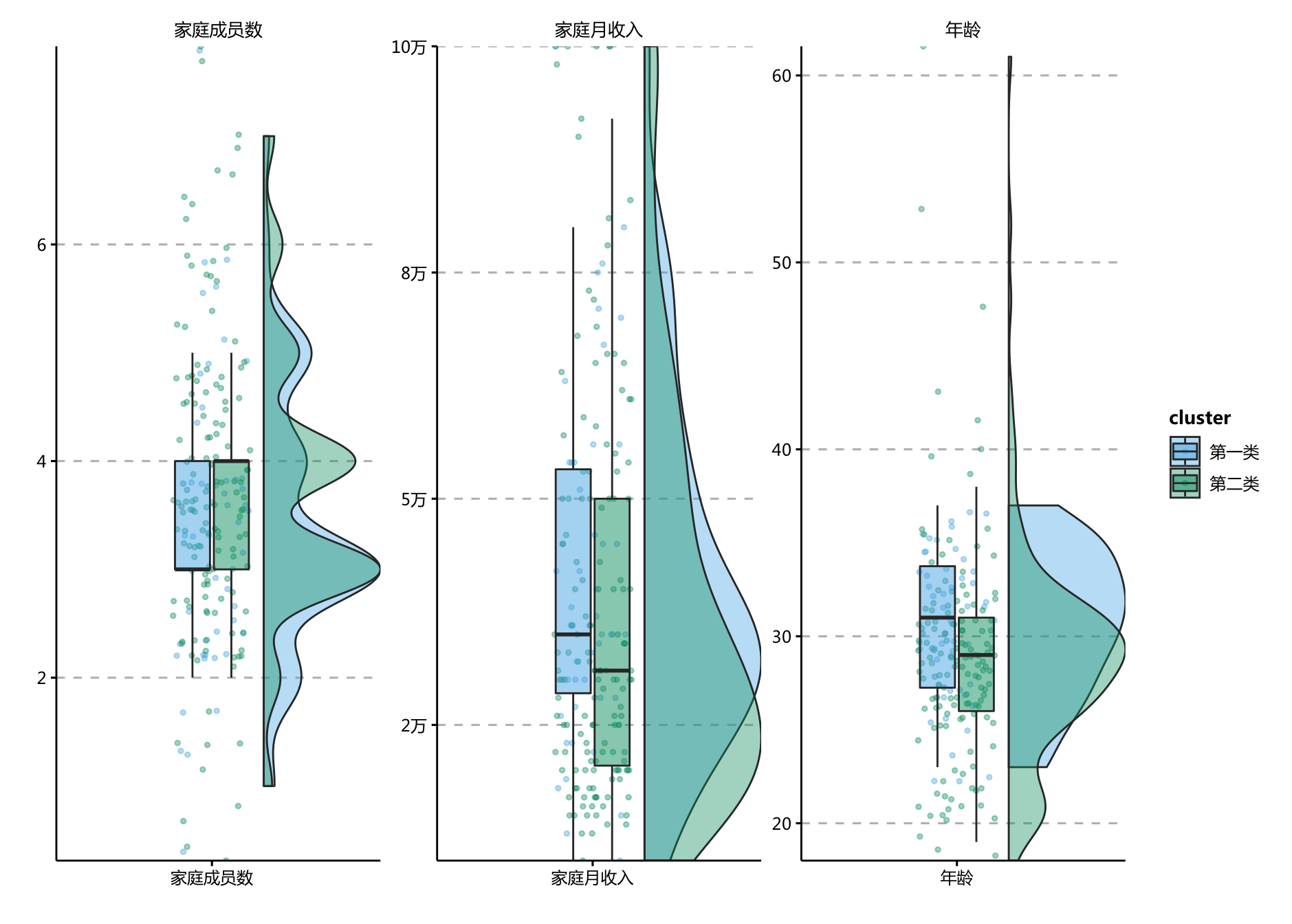
- 可以看到 目标的客户群体家庭年收入更高、年龄更大
4.2 推广方案
4.2.1 品牌认知
result %>%
select(cluster, contains("倾向")) %>%
group_by(cluster) %>%
pivot_longer(2:ncol(.),
names_to = "品牌") %>%
mutate(value = as.numeric(value)) %>%
group_by(cluster, 品牌) %>%
summarise(品牌渗透率 = sum(value, na.rm=T)/n()) %>% ungroup %>%
ggplot() +
aes(x = 品牌, fill = cluster, y = 品牌渗透率) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_manual(values = rev(get_blues(2))) +
ppt_theme +
coord_flip() 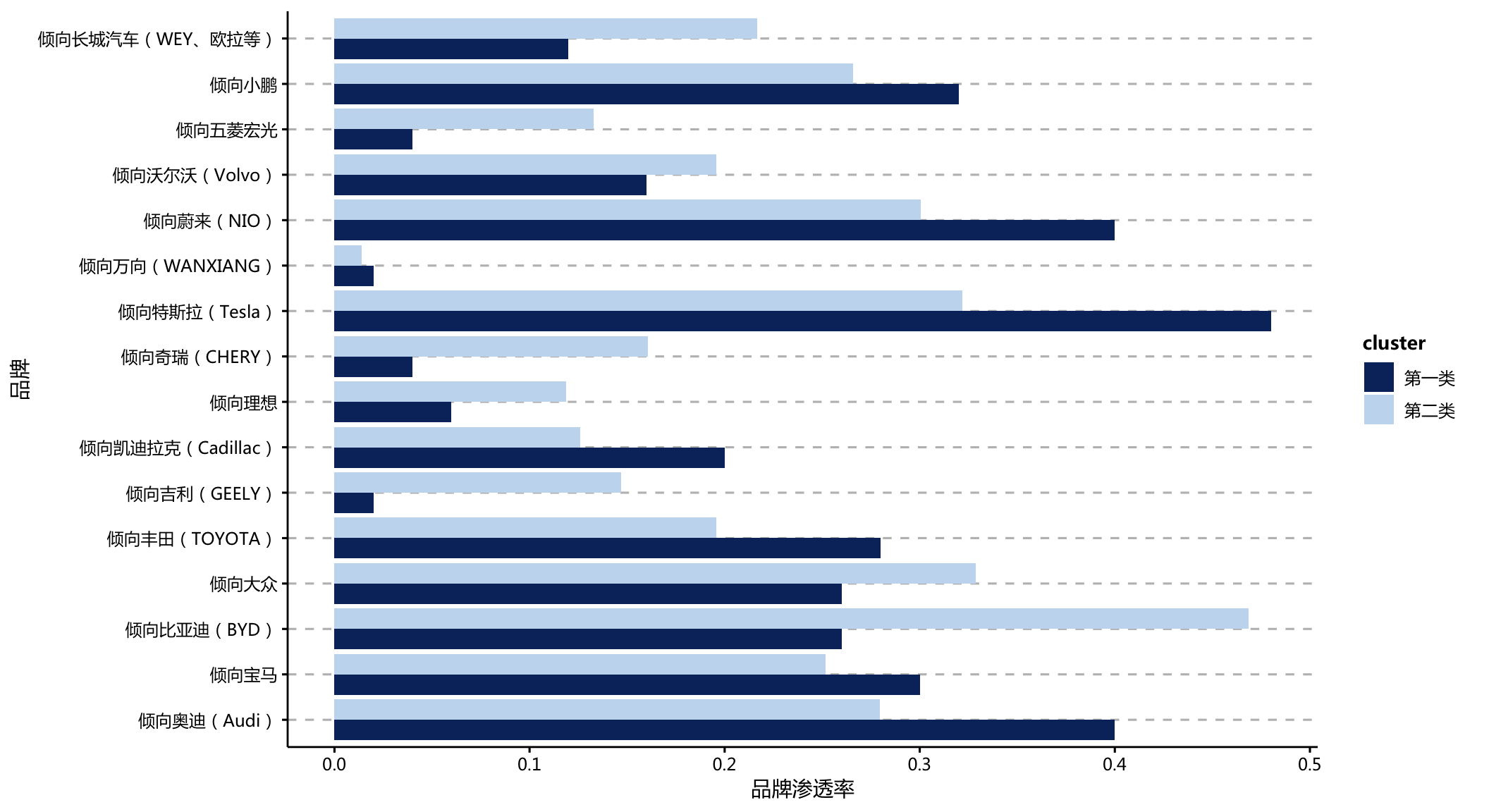
- 在不同品牌中,目标群体对特斯拉、奥迪等高价位牌子的购买倾向更高
4.2.2 资讯获取动力
result %>%
#mutate_at(c("了解程度","资讯获取主动度"), ) %>%
transmute(
cluster,
了解程度 = decode_knowledge(了解程度),
资讯获取主动度 = decode_check(资讯获取主动度)
) -> temp
temp %>%
group_by(cluster, 了解程度) %>%
summarise(占比 = n() ) %>%
group_by(cluster) %>%
mutate(占比 = 占比/sum(占比)) %>%
ggplot() +
aes(x = `了解程度`, y = 占比, fill = cluster) +
geom_bar(stat = "identity", position = "dodge") +
scale_x_discrete(position = "bottom", labels = function(x) gsub(",|、","\n",x)) +
coord_flip() +
scale_fill_manual(values = rev(get_blues(2))) +
ppt_theme + only_x +
theme(legend.position = "none") +
scale_y_reverse() -> p1
temp %>%
group_by(cluster, 资讯获取主动度) %>%
summarise(占比 = n() ) %>%
group_by(cluster) %>%
mutate(占比 = 占比/sum(占比)) %>%
#esquisser(temp)
ggplot() +
aes(x = `资讯获取主动度`, y = 占比, fill = cluster) +
geom_bar(stat = "identity", position = "dodge") +
scale_x_discrete(position = "top", labels = function(x) gsub(",|、","\n",x)) +
coord_flip() +
scale_fill_manual(values = rev(get_blues(2))) +
ppt_theme + only_x -> p2
p1 + p2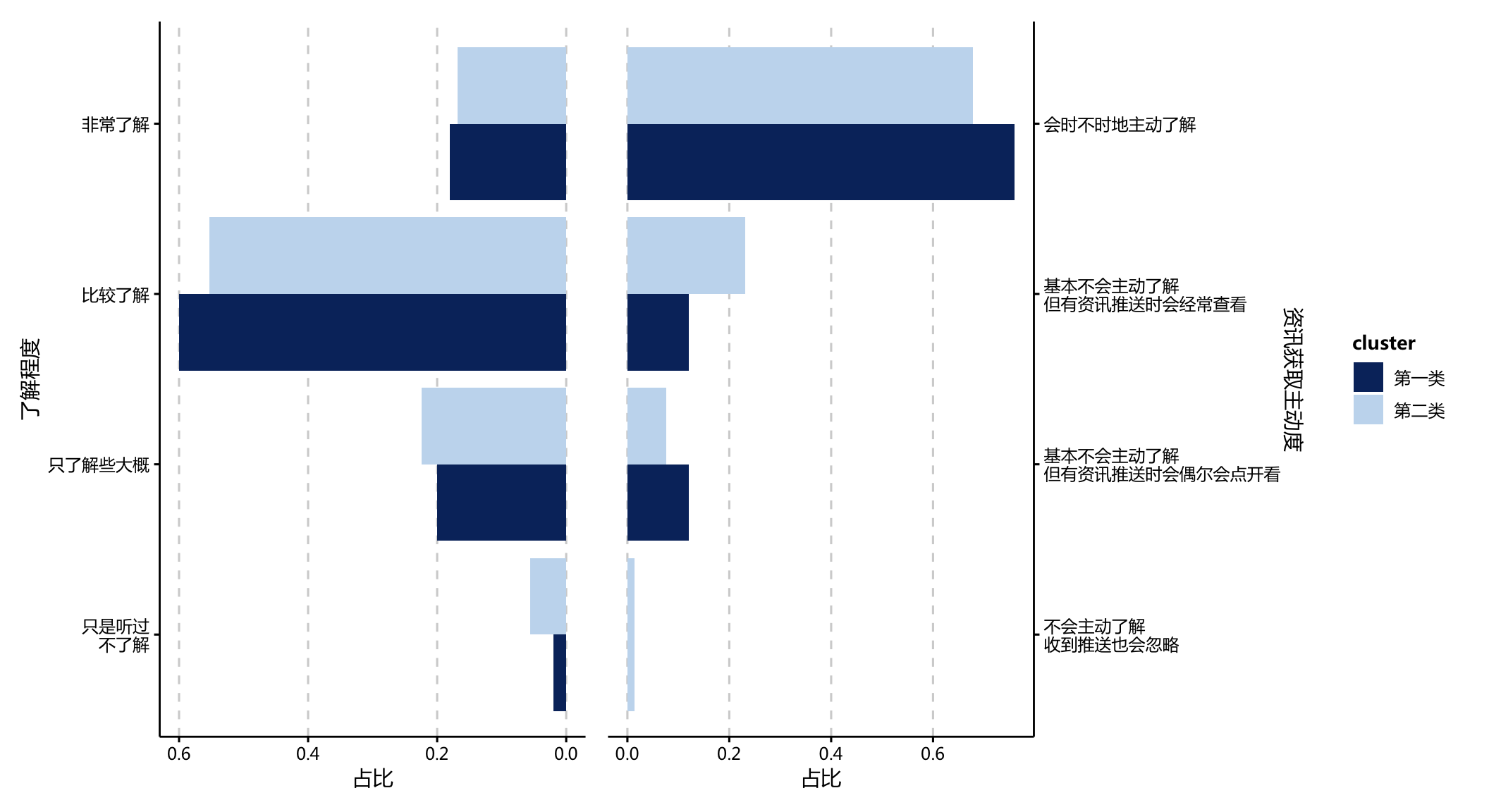
- 与此同时,第一类群体不仅了解程度更高,还会更主动地获取信息
4.2.3 资讯获取渠道
result %>%
select(cluster, 亲朋好友:其他) %>%
#mutate(cluster)
group_by(cluster) %>%
pivot_longer(2:ncol(.),
names_to = "渠道") %>%
mutate(value = as.numeric(value)) %>%
group_by(cluster,渠道) %>%
summarise(渠道渗透率 = sum(value)/n()) %>% ungroup -> temp
ggplot(temp) +
aes(x = `渠道`, fill = cluster, weight = `渠道渗透率`) +
geom_bar(position = "dodge") +
scale_fill_manual(values = rev(get_blues(2))) +
coord_flip() +
percenty +
ylab("占比") +
ppt_theme + only_x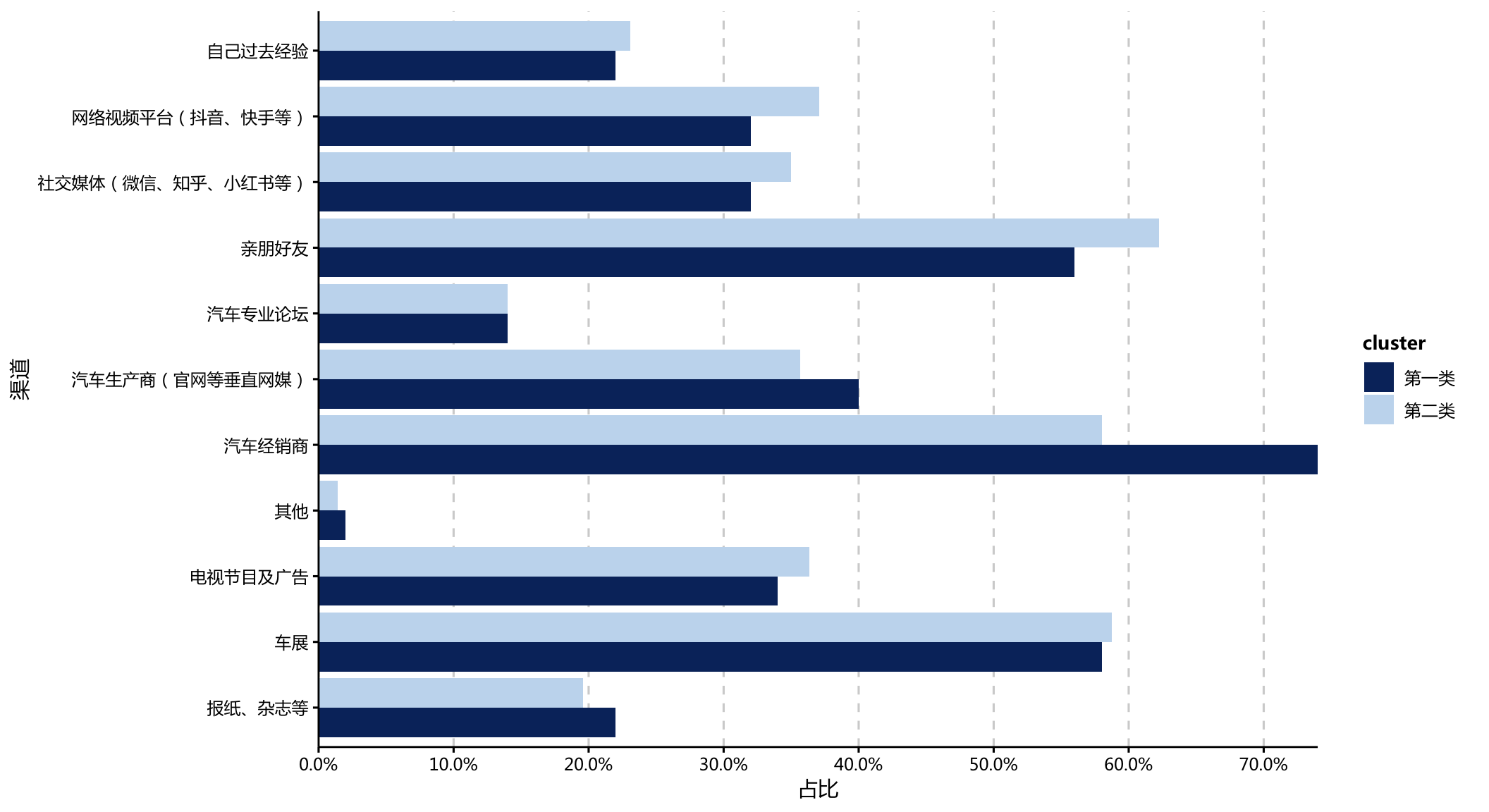
- 从渠道来看,第一类群体会从经销商等一手信息渠道中获取信息
result %>%
select(cluster, contains("从")) %>%
group_by(cluster) %>%
pivot_longer(2:ncol(.),
names_to = "渠道") %>%
mutate(value = as.numeric(value)) %>%
group_by(cluster,渠道) %>%
summarise(渠道渗透率 = sum(value, na.rm=T)/n()) %>% ungroup -> temp
ggplot(temp) +
aes(x = `渠道`, fill = cluster, y = `渠道渗透率`) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_manual(values = rev(get_blues(2))) +
coord_flip() +
percenty +# only_x +
ylab("占比") +
ppt_theme + only_x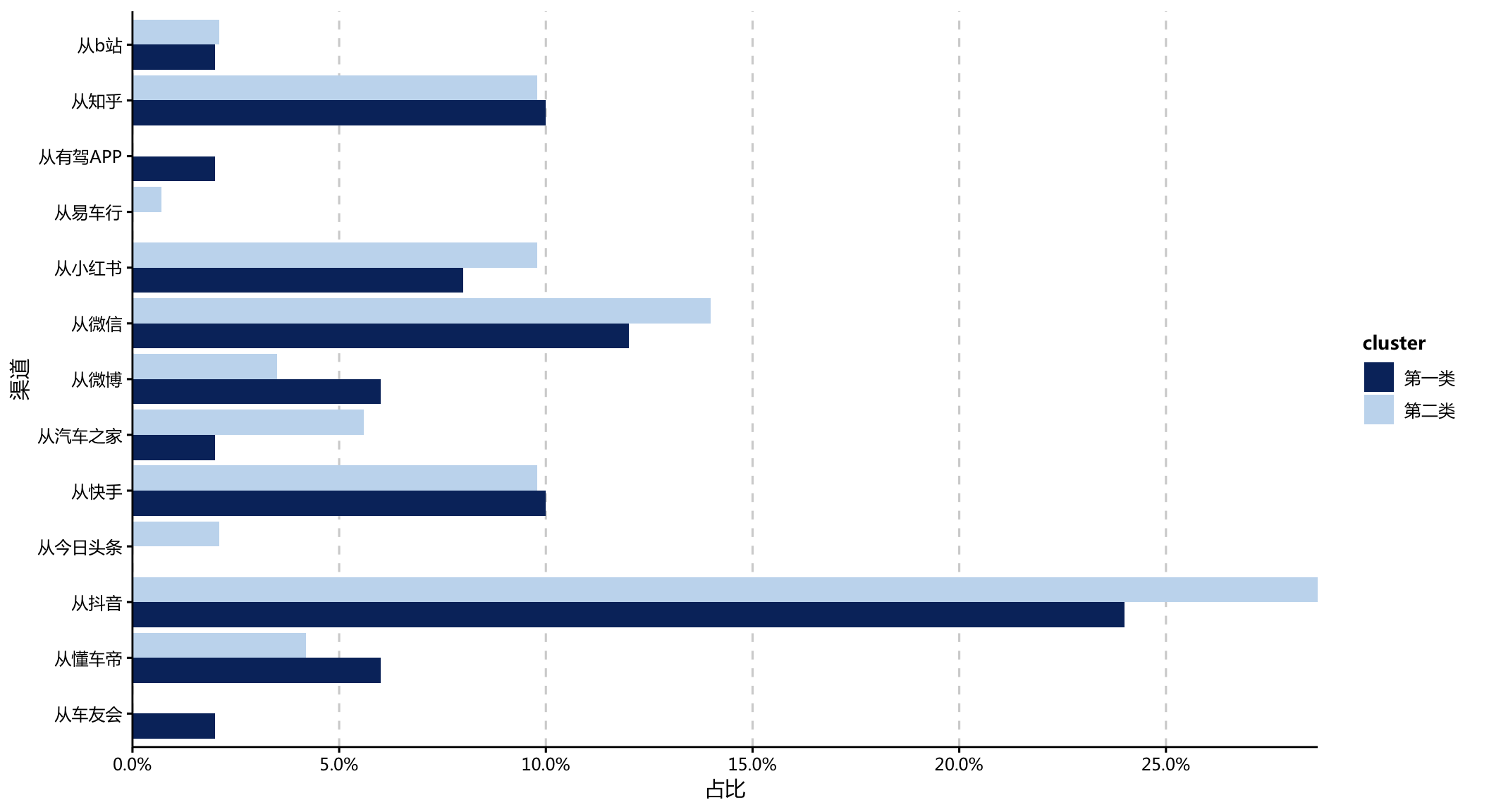
- 除此之外,抖音平台在两类群体中也相当高的渗透率,也适当放量广告