正则表达式
Contents
正则表达式¶
Online rebug: https://regex101.com/
基础¶
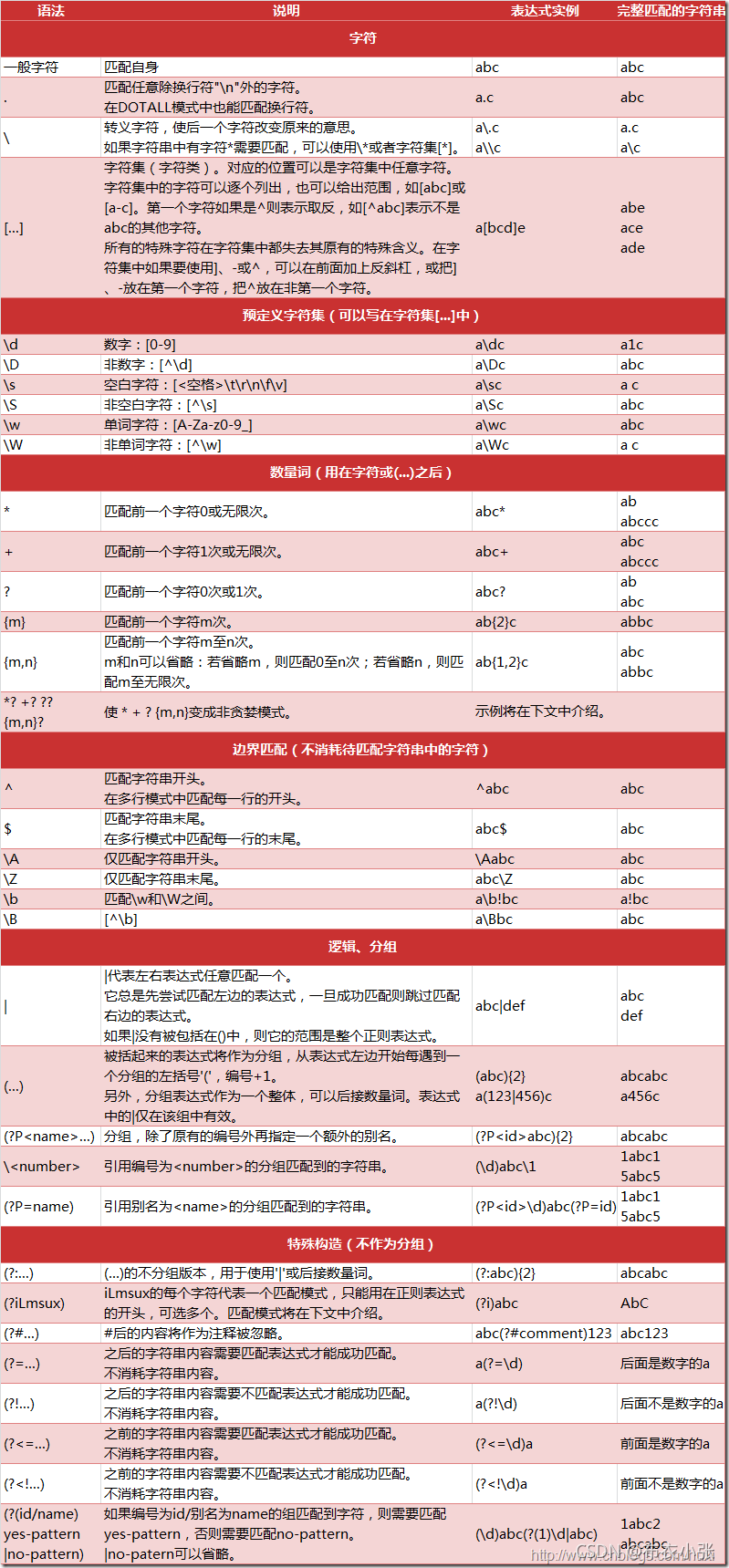
Lookahead 比如(?=foo): Asserts that what immediately follows the current position in the string is foo
Lookbehind 比如(?<=foo): Asserts that what immediately precedes the current position in the string is foo
Negative Lookahead 比如(?!foo): Asserts that what immediately follows the current position in the string is not foo
Negative Lookbehind: 比如(?<!foo): Asserts that what immediately precedes the current position in the string is not foo
import re
string = 'fox foxtrot ox box'
# fox字符
re.match(r'fox', string).group()
'fox'
# \w: 任意单个字符
re.match(r'[bf]ox', string).group()
'fox'
Python¶
re模块¶
re.match(): searches only from the beginning of the string and return match object if found. But if a match of substring is found somewhere in the middle of the string, it returns nonere.search(): search the regular expression pattern and return the first occurrence.re.findall(): search for “all” occurrences that match a given pattern
案例¶
清除某个模式内部¶
提取括号内的字符
text = '[(W)40(indo)25(ws )20(XP)111(, )20(with )20(the )20(fragment )20(en'
re.findall(r'\(([^()]+)\)', text)
['W', 'indo', 'ws ', 'XP', ', ', 'with ', 'the ', 'fragment ']
内层:
[^()]+表示:除了括号以外的任意字符出现1或无限次\(: 表示literally((): 表示识别的模式
提取在@和:之间的内容
text = '''\ RT @username: Tweet text
RT @abcde: Tweet text
RT @vwxyz: Tweet text
'''
re.findall('@([^:]+)', text)
['username', 'abcde', 'vwxyz']
@: 就是@(: start of a capture group[^:]+: one or more characters that are not :): close of the capture group
直到xxx¶
直到abc停止
text = "qwerty qwerty whatever abc hello abc "
re.search(r'.+?(?=abc)', text).group(0)
'qwerty qwerty whatever '
.+?: the un-greedy version of .+ (one or more of anything).When we use .+, the engine will basically match everything.
Then, if there is something else in the regex it will go back in steps trying to match the following part. This is the greedy behavior, meaning as much as possible to satisfy.
(?={contents}), a zero width assertion, a look around. This grouped construction matches its contents, but does not count as characters matched (zero width). It only returns if it is a match or not (assertion).group(0): can be be explained by comparing it with group(1), group(2), group(3), …, group(n).Group(0) locates the whole match expression.
Then to determine more matching locations paranthesis are used:
group(1) means the first paranthesis pair locates matching expression 1,group(2) says the second next paranthesis pair locates the match expression 2, and so on
各种Substring¶
包含三个词
可视化:
texts = ["I am good! I am so happy!", 'I am good', 'I am happy', 'goods makes customer happy']
for text in texts:
print(bool(re.search(r'^(?=.*happy)(?=.*good)', text)))
True
False
False
True
^: Assert start of the string 只是为了让正则anchor于开始,否则会有performance问题 link(?=.*happy): 在match到任何东西之前,lookahead看看有没有 「任何字符出现任意次+happy」这个pattern(?=.*good): 在match到任何东西之前,lookahead看看有没有 「任何字符出现任意次+good」这个pattern前两个连接起来:必须同时满足!
可视化:
for text in texts:
print(bool(re.search(r'^(?=.*\bhappy\b)(?=.*\bgood\b)', text)))
True
False
False
False