基础
Contents
基础¶
这一部分cover一些深度学习的基础概念!
基本概念¶
深度学习所处领域
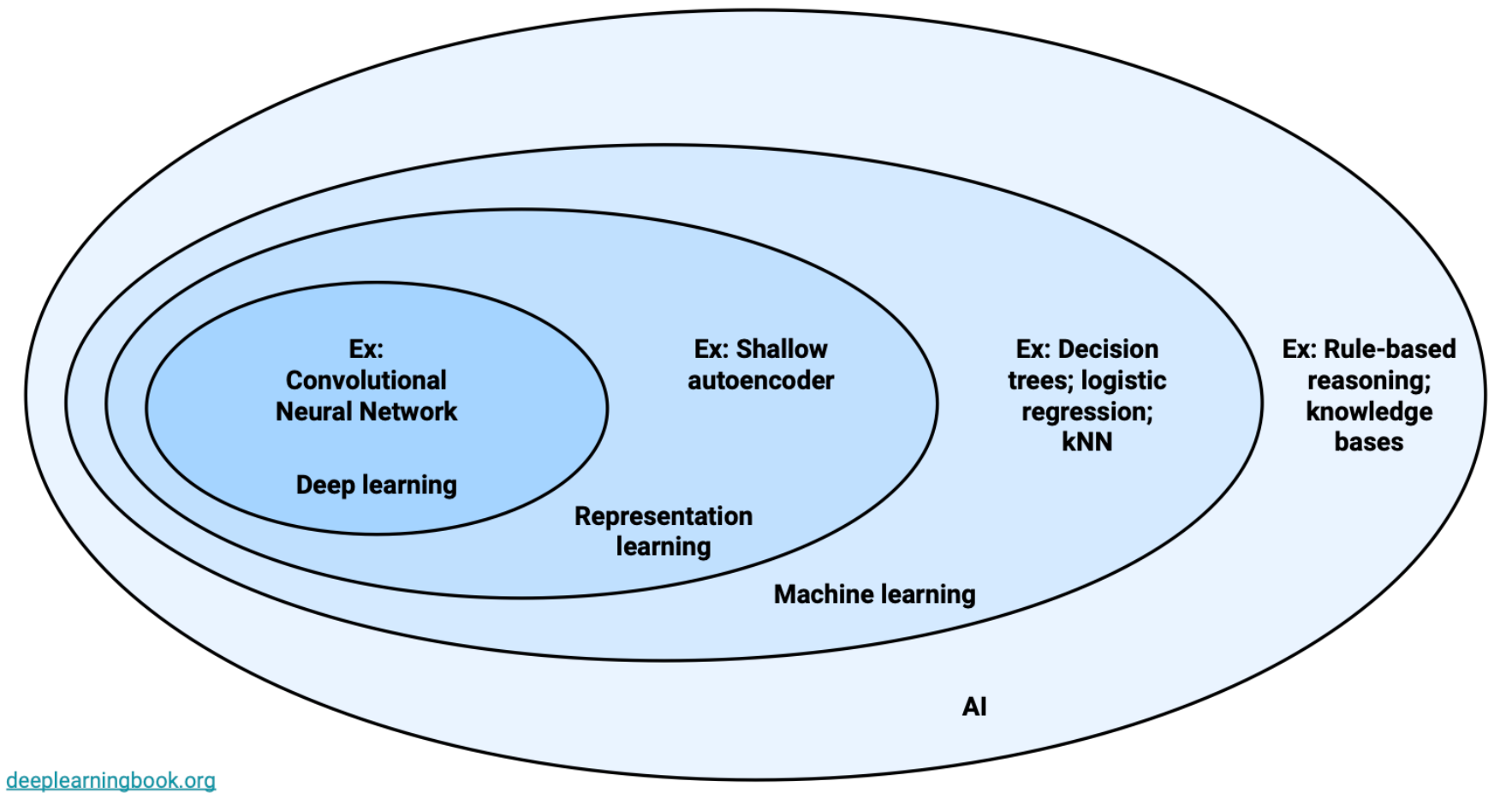
LR无法提取features,尤其是pixels类的,所以需要DL进行representation layers来做特征提取
与其用手动的特征 找猫的眼睛 e.g,可以让Neural Network automatically learn useful representation of data
模型训练
Epochs:一个epoch指的是用了trainset的所有数据进行了一轮训练
The longer you train your model, the more tightly it will fit the training data (but may also overfit the test data).
To find the right number of epochs, monitor the loss on the validation data when training. Stop training when the validation loss begins increasing (rule of thumb).
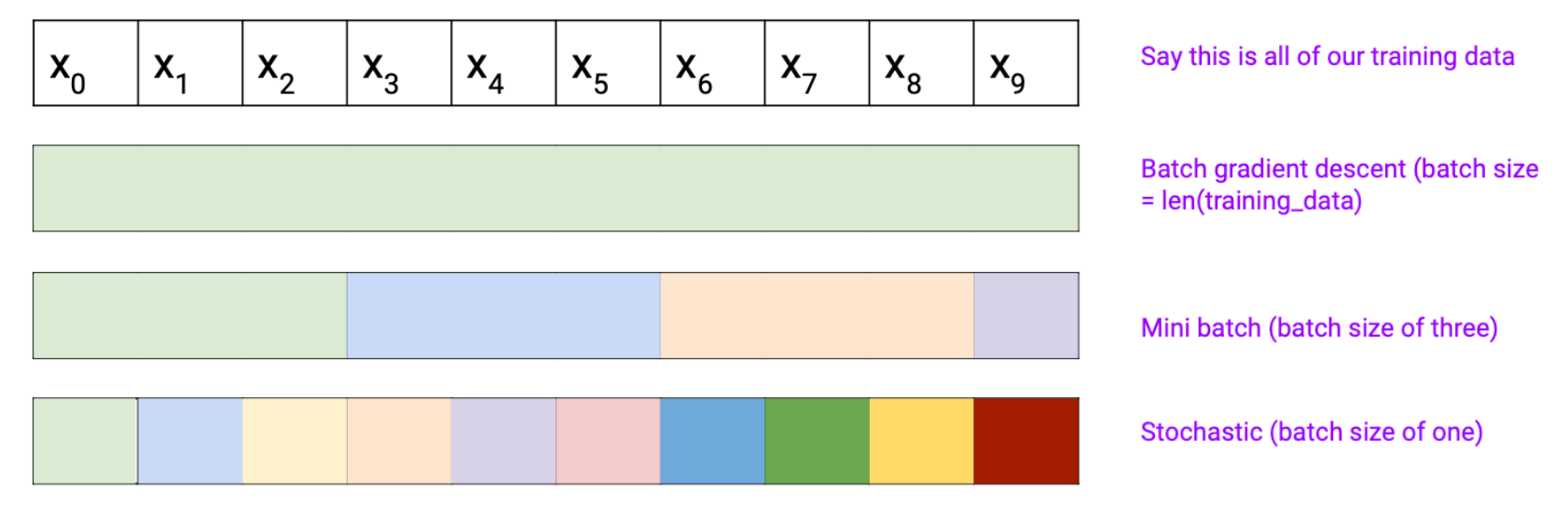
Batches:一次训练的时候只会用一个batch,# of batches越多越准确但更慢,有个speed-accuracy的
Batch Gradient Descent (Full data):只有一个batch(batch size就是length)
Mini batch Gradient Descent:现在经常被误称为Batch Gradient Descent
最后的example可以丢掉也可以as a smaller batch at the end,在上面的例子里**一个epoch有四个updates**
Stochastic: batch size = 1
Batch size:The number of examples used per gradient update.
A batch size of 1 is stochastic gradient descent. Many updates per epoch, but each is inaccurate.
A batch size of len(training_set) is batch gradient descent. One accurate update per epoch, but slow to compute.
Intermediate sizes (the default in Keras is 32) are called mini-batch gradient descent.
In general, you will not need to change this parameter unless your examples are very small (structured data, in which case you can use a larger batch size).
Early Stopping¶
Dropout¶
定义:Dropout is a regularization technique to deal with overfitting problem and improve generalization
dropout的含义:node is not used in this in the next round of training and and all its connections will be not be updated
dropout的方式:randomly dropout probability for each hidden layers
Prevents co-adaptation
of activation units
Each hidden unit learns certain features independently - the features that each neuron is learning our robust features they are not dependent upon the presence or not presence of the subsequence of the previous layers!
这样各个hidden unit学习的是different features
Probabilistically drop input features or activation units in hidden layers
Layer dependent dropout probability ( ~0.2 for input, ~0.5 for hidden)
为什么要input小:you do not want to use a high value of report for the input 因为 most the input features will be gone right in the training而我们希望保留!但也可以允许一定的dropout
Test的时候怎么处理dropout:apply dropout probability!这样test的时候其实layer都在